
Un de las piezas claves hoy en día de nuestro Internet que permite que funcione, son las Domain Name System o mayormente conocido como DNS. Este sistema de servidores DNS es el encargado de traducir los nombres de dominio que manejamos habitualmente, como mascandobits.es, en la dirección IP del ordenador donde está alojado ese dominio, que en el momento de escribir esta entrada es 31.220.20.199 .
Contextualización
Cada ordenador en Internet tiene una dirección IP que es única para ese ordenador (por lo menos en la red que pertenece). La IP está formada por cuatro números enteros de 0 a 255, separados por puntos. 127.0.0.1 es un ejemplo de dirección IP que además es especial porque hace referencia a nuestra propia máquina. Cada vez que te conectas a Internet, a tu ordenador se le asigna una dirección IP, puede ser siempre la misma o puede variar, lo normal es que cada vez que reinicies el router o al cabo de un tiempo obtengas una IP diferente.
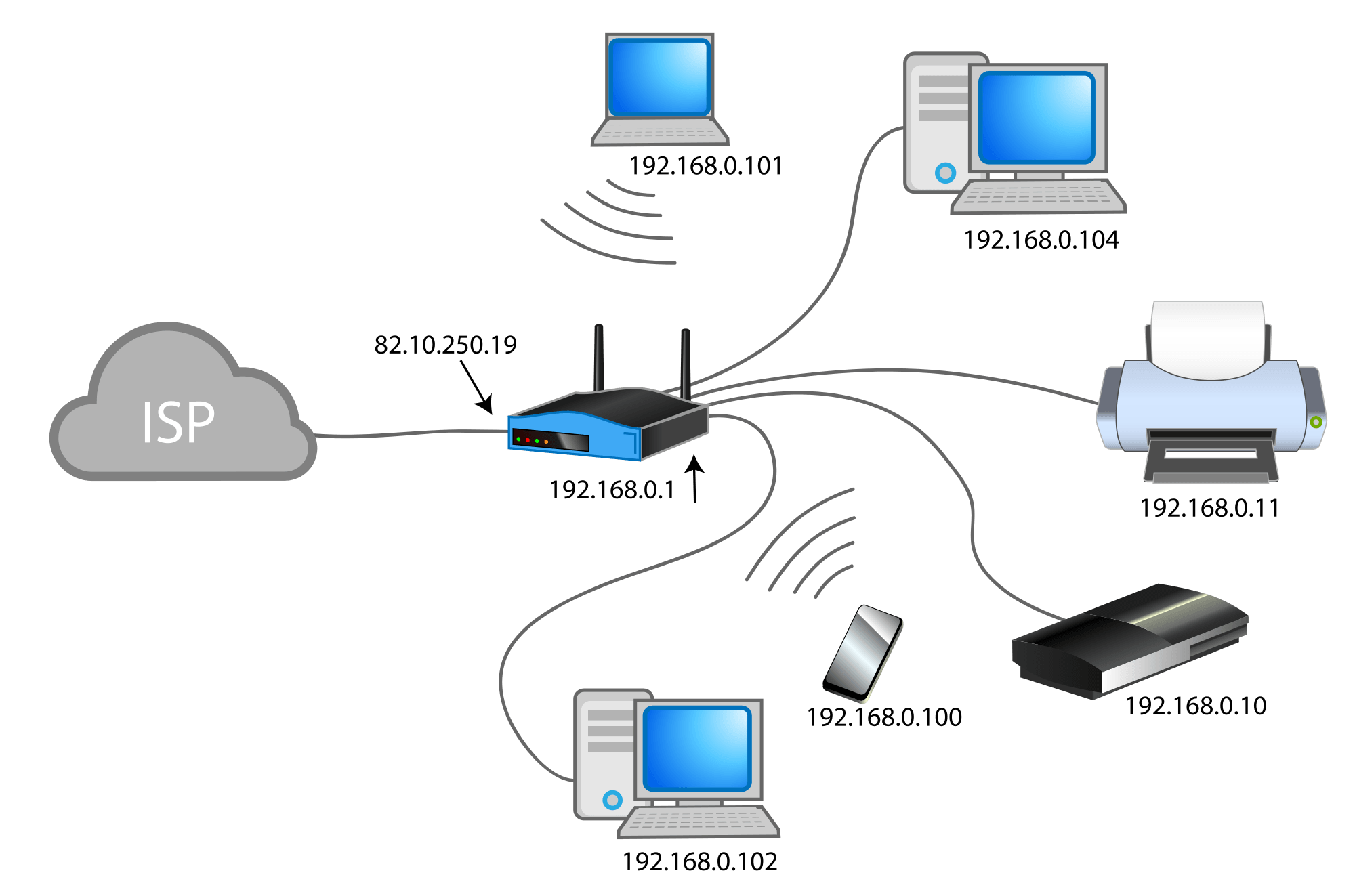
Esta IP que tiene tu equipo, y que te proporciona tu router, es privada y solo funciona en el rango de tu red local (dispositivos conectados a tu router). Existe un conjunto de rangos de IP que son usados como IPs privadas:
- 192.168.0.0 - 192.168.255.255 (65,536 direcciones IP)
- 172.16.0.0 - 172.31.255.255 (1,048,576 direcciones IP)
- 10.0.0.0 - 10.255.255.255 (16,777,216 direcciones IP)
El primer grupo de IPs lo puedes ver en la red local de tu casa o empresa (si es pequeña), el segundo grupo en empresas algo más grandes y el último grupo es común verlo para equipos conectados mediante VPN.
A su vez existe una segunda IP denominada pública que es la que tu ISP o proveedor de servicios te asigna al router y que sirve para poder acceder a Internet. Esta IP pública suele ser dinámica en la mayor parte de los casos y tu ISP se la asigna a tu router, normalmente reiniciando el router puede cambiar esta IP.
La conversión de una IP privada a una pública y viceversa se hace gracias a la Network Address Translation o NAT del router. Esto permite hacer peticiones a IPs publicas de servicios de Internet y devolver el tráfico de respuesta a la IP privada de la máquina que hizo las peticiones.
Un vez aclarado esta parte que es básica avancemos....
Los ordenadores donde están alojadas las páginas web o servicios tienen siempre la misma dirección IP, esto permite acceder dichos recursos siempre igual con la misma IP (a no ser que se cambie...). Sin embargo, cuando buscas una determinada página o servicios, en tu navegador no introduces la IP del ordenador donde está alojada, sino algo más sencillo de recordar, introduces un nombre de dominio, como mascandobits.es. Adicionalmente he dicho que normalmente no se cambia la IP de la web o servicio, pero puede darse el caso por ejemplo de que se quiera mover la web o servicio a otra máquina que muy seguramente tenga otra IP pública. Gracias a las DNS este problema queda cubierto, ya que simplemente basta con asociar el dominio con la nueva IP pública.
Cuando escribes en tu navegador el nombre de una web o servicio, lo que hace tu ordenador es preguntar a tu servidor local DNS (el que te indica tu router por DCHP) por la dirección IP del ordenador donde está alojada esa página o servicio. El servidor DNS es una gran base de datos con infinidad de traducciones de nombres de dominio a dirección IP. Esa base de datos es distribuida y compartida con otros proveedores y sus respectivos servidores DNS. Si el nombre de dominio que estás buscando no está en tu DNS local, éste realizará una petición a otros DNS de la red hasta encontrar la traducción adecuada. Estas bases de datos guardan en caché durante unos días esas traducciones de nombre de dominio a IP, por eso a veces sucede que si una web o servicio cambia de servidor, puede que desde algunos lugares del planeta se acceda a la web o servicio y desde otros no, porque hay ordenadores que cuando preguntan por la página, el servidor DNS los envía a la antigua dirección IP y no a la nueva.
Además de los servidores DNS, nuestro ordenador también guarda un caché de las DNS, y si hemos visitado recientemente una página web, nuestro ordenador ya no preguntará al servidor cuál es la dirección IP de la página, sino que se dirigirá a la que ya tiene almacenada. Esta caché puede borrarse.
Para borrarla desde Windows:
ipconfig /flushdns
Para borrarla desde GNU-Linux:
sudo /etc/init.d/nscd restart //si usas nscd dns cache sudo /etc/init.d/dnsmasq restart //si usas dnsmasq dns cache sudo /etc/init.d/named restart //si usas bind dns cache sudo /etc/init.d/bind9 restart //(alternativa) si usas bind dns cache
Configurar servidor DNS caché
Las DNS constituyen la columna vertebral del funcionamiento de Internet y dado su función constituye un riesgo una mala gestión de los DNS globales que son gestionados por la ICANN, una asociación sin ánimo de lucro. Existen 7 llaves que dan acceso físico a los DNS y que se reparten entre 14 personas, 7 titulares y 7 suplentes. Son los garantes de que los DNS no sean atacadoso o modifcados de manera no deseada:
- https://www.xataka.com/seguridad/la-seguridad-de-internet-depende-de-siete-llaves-maestras-custodiadas-por-14-personas
- https://www.genbeta.com/seguridad/siete-llaves-y-un-destino-la-seguridad-de-internet-y-los-dns
Como puedes deducir el acceso a la resolución de DNS es algo que puede ser muy crítico. La ICANN sólo constituye el registro de una parte de Internet, aunque habitualmente se suelen usar sus DNS como referencia, ya que a su vez las operadoras que dan acceso a Internet (ISP) tienen sus propio DNS que van configurados en nuestro router y los cuales podemos cambiar por otros que sean de nuestro agrado.
Controlar las DNS y cómo se resuelven es algo que puede ser ventajoso, sobre todo si tenemos dentro de nuestra red local el servidor DNS y la resolución de dominios tiene una menor latencia. Para crear nuestro DNS caché lo podemos hacer con una Raspberry Pi conectada a nuestra red local de casa. Una Raspberry Pi consume como un móvil cargando y puede servirnos perfectamente para este cometido de acelerar las peticiones de resolución de DNS.
Accedemos a nuestra Raspberry Pi por SSH e introducimos el siguiente comando:
sudo apt-get install bind9 dnsutils
Con esto instalamos bind y además instalamos la herramienta dig (con el paquete dnsutil) que más adelante ya veréis para qué sirve.
Un vez instalado vamos a /etc/bind/named.conf.options, puedes configurarlo con el siguiente comando:
sudo nano /etc/bind/named.conf.options
Lo puedes configurar con la siguiente información:
forwarders {
208.67.222.222;
208.67.220.220;
};
Es posible que tengas que quitar la // para que tenga efecto. Todo lo que va precedido con // se trata como un comentario. Yo he usado como forwarders las DNS de OpenDNS, pero puedes usar las que quieras o añadir otras.
Ahora recargamos las configuraciones con el siguiente comando:
rndc reload
Ya tenemos funcionando nuestro servidor DNS cacche. Para comprobar la diferencia de tiempos de resolución vamos a hacer la siguiente prueba. Vamos a resolver las peticiones contra las DNS de Google (8.8.8.8) (se asume que son de lo mejorcito 😉 ) y contra nuestro nuevo servidor DNS caché en la Raspberry Pi.
Introducimos el siguiente comando para comprobar el tiempo de respuesta para la resolución del dominio mascandobits.es con las DNS de Google:
dig mascandobits.es @8.8.8.8 ; <<>> DiG 9.9.5-9+deb8u13-Raspbian <<>> mascandobits.es @8.8.8.8 ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 28184 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;mascandobits.es. IN A ;; ANSWER SECTION: mascandobits.es. 2684 IN A 31.220.20.199 ;; Query time: 42 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Thu Oct 26 19:11:51 CEST 2017 ;; MSG SIZE rcvd: 60
Nos devuelve 42 msec, que no está anda mal, pero vamos a ejecutar lo mismo usando nuestro DNS de la Raspberry Pi. Lo haremos dos veces, ya que la primera vez le costará un tiempo similar, o algo mayor, ya que deberá ir a buscar la resolución del dominio a los forwarders que configuramos la primera vez, en mi caso a los DNS de OPenDNS. Para la segunda ejecución os debería salir algo así:
dig mascandobits.es @127.0.0.1 ; <<>> DiG 9.9.5-9+deb8u13-Raspbian <<>> mascandobits.es @127.0.0.1 ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 59435 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 7, ADDITIONAL: 14 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 4096 ;; QUESTION SECTION: ;mascandobits.es. IN A ;; ANSWER SECTION: mascandobits.es. 2575 IN A 31.220.20.199 ;; AUTHORITY SECTION: es. 146250 IN NS a.nic.es. es. 146250 IN NS ns-ext.nic.cl. es. 146250 IN NS ns1.cesca.es. es. 146250 IN NS f.nic.es. es. 146250 IN NS ns3.nic.fr. es. 146250 IN NS sns-pb.isc.org. es. 146250 IN NS g.nic.es. ;; ADDITIONAL SECTION: a.nic.es. 146250 IN A 194.69.254.1 a.nic.es. 146250 IN AAAA 2001:67c:21cc:2000::64:41 f.nic.es. 146250 IN A 130.206.1.7 f.nic.es. 146250 IN AAAA 2001:720:418:caf1::7 g.nic.es. 146250 IN A 204.61.217.1 g.nic.es. 146250 IN AAAA 2001:500:14:7001:ad::1 ns1.cesca.es. 146250 IN A 84.88.0.3 ns1.cesca.es. 146250 IN AAAA 2001:40b0:1:1122:ce5c:a000:0:3 ns3.nic.fr. 146250 IN A 192.134.0.49 ns3.nic.fr. 146250 IN AAAA 2001:660:3006:1::1:1 ns-ext.nic.cl. 146250 IN A 200.1.123.14 sns-pb.isc.org. 146250 IN A 192.5.4.1 sns-pb.isc.org. 146250 IN AAAA 2001:500:2e::1 ;; Query time: 1 msec ;; SERVER: 127.0.0.1#53(127.0.0.1) ;; WHEN: Thu Oct 26 19:11:40 CEST 2017 ;; MSG SIZE rcvd: 495
Hemos bajado a 1 msec, que es bastante mejor que el tiempo de las DNS de Google. Además esto nos demuestra que se consigue bastante velocidad, en mi caso 42 veces más rápido para un dominio cacheado previamente por el servidor DNS de la Raspberry Pi.
Ahora para que todos los dispositivos de tu red usen estas nuevas DNS, lo más fácil es configurarlo en el router. Yo tengo un router de TP-Link, pero la configuración suele ser similar en todos los routers. Lo que nos interesa suele estar en la sección "DCHP":

En el DNS Server he añadido la IP de la Raspberry Pi donde está el servidor DNS, es recomendable para ello que asignes IP estática a la Raspberry Pi. Hoy en día lo puedes hacer fácil desde el propio router asociando una IP privada a la MAC de la Raspberry Pi. El Secondary DNS Server lo he dejado con 0.0.0.0 para que lo resuelva contra el modem-router de proveedor de servicio a Internet (ISP). Esto hace que si la Raspberry Pi deja de funcionar, la red puede seguir resolviendo los dominios contra las DNS que me proporciona el router de mi ISP. Hay que cubrirse siempre 😉 !.
Con esto ya estaría listo, pero para dejarlo todo bien atado vamos a volver a la consola SSH de la Raspberry Pi para comprobar si bind arrancará al inicio si la apagas y enciendes. Para ello vamos a introducir el siguiente comando:
service bind9 status
● bind9.service - BIND Domain Name Server
Loaded: loaded (/lib/systemd/system/bind9.service; enabled)
Drop-In: /run/systemd/generator/bind9.service.d
└─50-insserv.conf-$named.conf
Active: active (running) since jue 2017-10-26 10:25:49 CEST; 5h 18min ago
Docs: man:named(8)
Main PID: 17478 (named)
CGroup: /system.slice/bind9.service
└─17478 /usr/sbin/named -f -u bind
Si en la línea de "Loaded" vemos al final "enabled"es que está activado como servicio al arranque. Si no fuera así bastaría con ejecutar el siguiente comando:
sudo systemctl enable bind9
Si quieres ver de manera general todos los servicios que tienes corriendo puedes ejecutar:
service --status-all
Podremos ver los servicios que existen y si están arrancados o no.
Con esto ya queda tu red perfectamente configurada para usar tu propio servidor DNS caché alojado en tu Rapsberry Pi para toda tu red local y mejorar los tiempos de respuesta de la resolución de dominios.