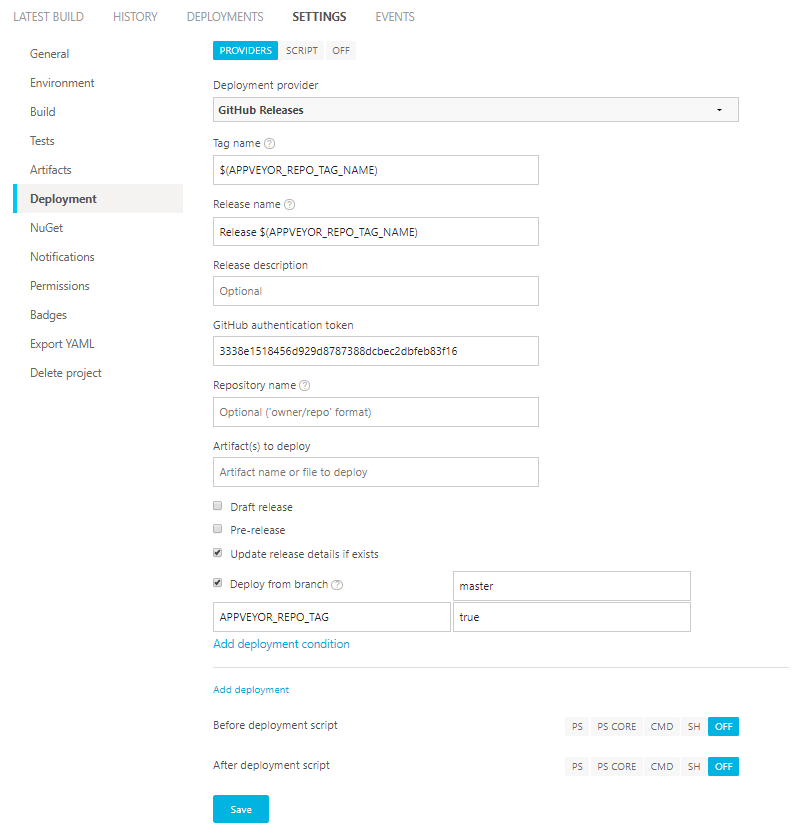

Cada vez suele ser más normal ver la figura del ingeniero de software que se dedica a la gestión de proyectos, gestionando las ramas de desarrollo (develop & features) y la rama estable master (recientemente normalizada como main).
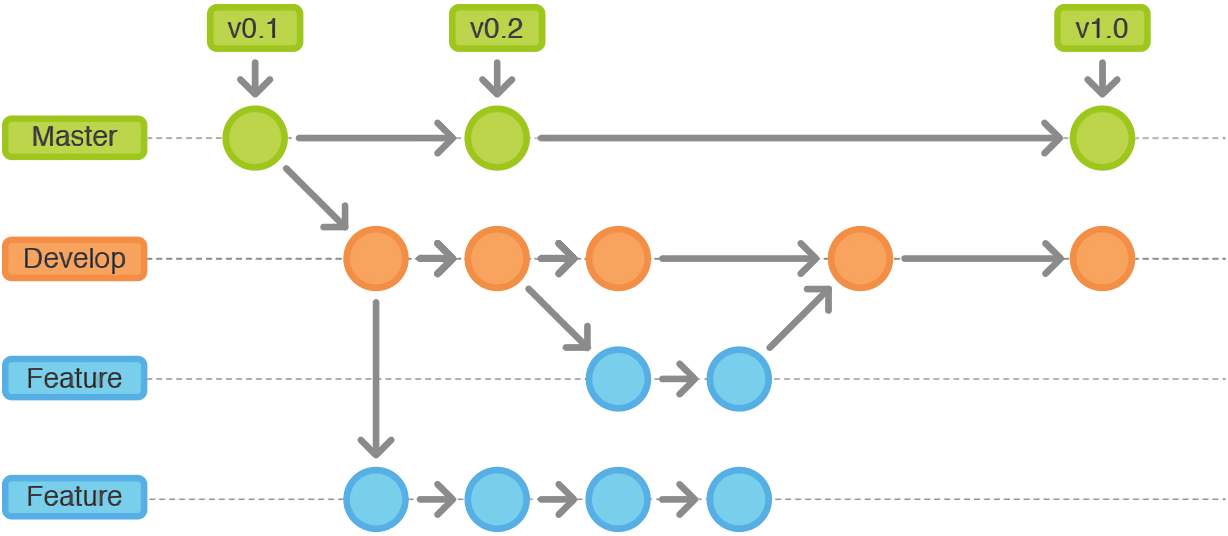
Imagen obtenida de la presentación Desarrollo Colaborativo de Software
Muchas veces sin querer se usan las herramientas de "merge" de código de manera incorrecta sin pararse a pensar en los beneficios y "contraprestaciones" que puede tener hacerlo de una forma u otra. Es por ello que este artículo, pretende arrojar algo de luz en qué nos puede convenir hacer en cada momento.
Antes de nada vamos a aclarar la notación para que resulte todo más sencillo. Nos referiremos a la rama Base, como la rama a la que se desea fusionar los cambios en el proceso de merge. Por otro lado nos referiremos a la rama Head como la rama que contiene los cambios que queremos incluir en la rama Base. Estos cambios en términos de plataformas para el desarrollo colaborativo de software como GitHub, GitLab, Bitbucket o Gogs, se suele aplicar con frecuencia en los conocidos como Pull Request (PR). Una solicitud formal a la inclusión de código de un desarrollador o grupo de desarrolladores externo al equipo de desarrolladores de un repositorio, la cual puede ser revisada y probada antes de realizar el merge.
La rama Base más habitual es la master o main que es asumida además como rama estable del desarrollo en un repositorio de manera generalizada. Los puntos más estables y que deberías usar son los denominados Tags de versión que son puntos específicos donde se ha trabajado una estabilidad específica que suele cerrar una iteración de desarrollo que incluye mejoras y soluciones a fallos conocidos desde la anterior versión.
Porque sale fuera de alcance de este artículo, no mencionaremos toda la problemática y gestión inherente que puede aparecer en forma de conflicto cuando realizamos un merge de código. Conflictos que deberán ser resueltos para asegurar la coherencia y estabilidad de la rama Base. Y que dicho sea de paso, suelen ser producidos muchas veces por falta de comunicación o por no ser "aséptico" en la forma de programar, refactorizando el código más de la cuenta o cuando no toca, por tener un mal diseño de clases o funciones... o incluso por aplicar la regla del scout que se resume en "Dejar las cosas mejor de como te las encontraste". Esto último puede convertir en un infierno la tarea de la persona que se dedica a integrar cambios y aportes externos si no se gestiona correctamente o falla el proceso de comunicación. Los potenciales conflictos por cambios en el código, es la causa número uno por la que una propuesta de cambio (PR) acaba por no integrarse al código finalmente y por consecuencia genera frustración y pérdida de tiempo.

Merge
La opción de hacer un merge de varios commits de una rama (Head) o hacer un merge de un PR es la acción habitual y predeterminada. Al realizar el merge todos los commits de la rama Head se fusionarán con los de la rama Base.

Estado inicial

Tras aplicar el merge
En esta ilustración, la rama Head se bifurca desde el segundo commit en la rama Base. Se sugieren algunos cambios como nuevas confirmaciones en la rama Head y ahora deben actualizarse en la rama Base. Mediante el merge, las confirmaciones se agregan a la rama Base como se muestra en la imagen superior.
No obstante el ejemplo presentado resulta una visión simplificada, existiendo dos posibles formas de hacer el merge dependiendo de la casuística en la inclusión o no del merge commit.
Fast-Forward o No Fast-Forward 🤔
En el primer caso, el merge fusiona lo cambios y añade los commits de la rama Head en la rama Base. Esto es posible siempre y cuando los commits se produzcan en la rama Head. Básicamente lo que se produce es un desplazamiento del puntero (fast-forward) de la rama Base al último commit de la rama Head.

master = Base | feature = Base
En el segundo caso, con el merge se añade un commit adicional en la rama Base que deja constancia de la unión de la rama Head con la rama Base. Este commit adicional aparece, bien porque lo forzamos para que no se produzca un fast forward (--no-ff); o bien porque la rama Base también contenía cambios, existiendo cambios en ambas ramas en el momento de la fusión.

Squash + Merge
Squash y merge combina todos los commits de la rama Head en un único commit y luego fusiona la rama Head con la rama Base. De esta manera, el historial de commits de la rama Head queda simplificado en un único commit en la rama Base.
Estado inicial

Tras aplicar squash + merge
Se puede observar que la rama Head se bifurca desde el segundo commit de la rama Base y se agregan dos nuevos commits que se añaden a la cabecera de la rama Base. Mediante squash y merge, ambos commits (6 y 7) se combinan en una único commit y luego se fusionan en la rama Base como se muestra en la imagen superior.
Rebase + Merge
Rebase y merge agrega todas los commits en la rama Head de manera individual a la rama Base sin un merge commit. Para todas los hotfix y commits puntuales que no se puedan fusionar con otros commits, esta es la opción de referencia. Esto es debido a que a no existe relación de parentesco con los commits preexistentes del propio árbol.
Cuando se hace una reorganización con rebase en el flujo de los commits de una rama, el SHA único de cada commit cambia debido a que además del contenido del commit para la formación del hash SHA, también se tiene en cuenta el parentesco con el commit inmediatamente anterior y por consiguiente del árbol completo. Este hecho provoca que el uso de rebase provoque más conflictos y su gestión sea más complicada. Esta gestión es complicada, es debido a que Git principalmente usa los commits comunes como base de parentesco, el contenido del propio commit y su contexto (líneas de código anteriores y posteriores a cada cambio de un commit); y en el caso del rebase por causa de la reorganización, no se cuenta con la base de parentesco.

Estado inicial

Tras aplicar rebase + merge de la rama Base a la rama Head

Tras aplicar rebase + merge de la rama head a la rama Base
Atendiendo a la ilustración, la rama Base se bifurca en el segundo commit para formar la rama Head. Posteriormente, se agrega un nuevo commit a la rama Base. Mientras tanto, los commits se realizan en la rama Head.
Por causa del rebase y merge de la rama de la Base a la rama Head, la base de la rama Head se vuelve a colocar. Es decir, ahora la rama Head se bifurca desde el nuevo tercer commit para que el nuevo commit de la rama Base se incluya en la rama Head. Y luego, se aplican los commits en la rama Head.
Ahora, para actualizar la rama Base con los últimos commits de la rama Head, el rebase se realiza de la rama Head a la rama Base como se muestra en la imagen superior.
GitHub
En GitHub podemos ver estas 3 opciones, siendo el ejemplo más habitual e ilustrativo cuando estamos revisando un PR y finalmente decidimos incorporar los cambios:

Haciendo click en la flecha que apunta hacia abajo al lado del "Merge pull request", podremos ver las tres formas de hacer merge que hemos mencionado. De manera análoga GitLab, Bitbucket o Gogs presentan las mismas opciones, o muy similares.
Conclusiones
Tras ver todas las opciones de merge, es recomendable tener en Git cuanta más traza mejor, eso incluye la creación del merge commit evitando el fast-forward si con ello podemos mejorar la traza de la rama donde existían los cambios que se fusionan a la rama Base.
Pero si trabajas en proyectos grandes o eres el gestor de la ramas de desarrollo de un repositorio con suficientes desarrolladores implicados, es más que seguro usarás squash y merge para compartimentar mejor los commits de cada desarrollador. Eso sí asegúrate de tener un buen sistema de CI como Travis CI o AppVeyor, así como suficientes pruebas unitarias, porque el problema de juntar varios commits en uno, es la imposibilidad de revertir los commits parciales una vez que se han juntado.
Por último el uso de rebase y merge es recomendable hacerlo como última opción y en caso de que squash y merge no sean suficiente o se quiera tener la trazabilidad manteniendo los commits parciales de las ramas que se fusionan (hotfix, commits puntales, excesiva densidad de ramas del árbol de versionado Git...), pudiendo realizar así una regresión limpia y más fácil de seguir. La principal desventaja de este método es que se pierde trazabilidad cronológica por la reorganización y potencialmente aumentan los conflictos, pero a la vez se gana simplicidad y claridad en el árbol debido a que no genera una densidad de ramas que complique su gestión. Además, también es posible revertir cualquier commit parcial, pero esto pierde relevancia, cuando se asume que existen servicios de CI que deberías estar ya usando que pueden hacer correr tus pruebas unitarias y ahorrarte sufrimiento y sobresfuerzo innecesario.