Una de las formas más eficientes de gestionar la adhesión de subproyectos y librerías en Git, es mediante el uso de submódulos que nos permiten trabajar con ellos dentro de un proyecto, o de manera desacoplada con cada submódulo como si fuera un repositorio Git.
La creación de un submódulo dentro de un proyecto se limita a ejecutar el siguiente comando dentro del directorio deseado en el que se quiera añadir el submódulo, dentro de la raíz del proyecto:
git submodule add http://porject-url
Donde la URL después del comando "add" indica la localización del proyecto Git que queremos montar como submódulo.
Si deseas clonar el repositorio e incluir en el clonado los submódulos, deberás hacer un clone recursivo:
git clone --recursive http://porject-url
Donde deberás especificar la URL del proyecto.
Si no realizas el clonado recursivo, del proyecto deberás realizar una inicialización manual de los submódulos:
git submodule init
git submodule update
Por otro, lado, igual que es interesante crear un submódulo dentro del un proyecto, lo es también eliminar un submódulo de un proyecto. Por ejemplo porque queramos moverlo de sitio o porque queramos prescindir de él. Para ello os explicaré la forma de hacerlo borrando el repositorio, que puede servir para conseguir ambos objetivos.
Escontrándonos en la raíz del proyecto que contiene el submódulo que queremos borrar ejecutamos los siguientes comandos:
# Desinicializamos el submódulo de la lista de submódulos
git submodule deinit path/submodule
# Borramos físicamente el directorio del submódulo
git rm path/submodule
# Eliminar cache del árbol de trabajo de Git
git rm --cached path/submodule
# Eliminamos la meta información del submódulo que por alguna razón no borra Git
rm -rf .git/modules/path/submodule
Con las sucesión de comandos detallados, desvincularás totalmente el submódulo deseado y eliminarás los archivos innecesarios.
De esta forma queda cubierta la gestión de submódulos Git en su carácter más esencial, siendo una herramienta muy potente a la hora de gestionar las dependencias de un proyecto, y a la vez facilitando la actualización de las mismas.
La Informática e Internet es una piña de estándares que muchas veces a los desarrolladores nos son transparentes. Esto provoca que habitualmente no nos formulemos la pregunta de cómo se codifica, se procesa y se manda una dato, ya que existen funciones de alto nivel que nos resuelven dicha problemática o simplemente se realiza de manera transparente al desarrollador mediante un Framework o Librería.
¿Alguna vez te has preguntado cómo se codifican los caracteres que escribes? La verdad es que esto de la informática nació en los Estados Unidos y su Silicon Valley. Esto hace obvio que las codificaciones se pensaron para el inglés.
Con el tiempo la informática se extendió hasta su uso normalizado que tenemos hoy en día. El problema que tuvimos los de habla latina era que la codificación de base era UTF-8 y no incluía nuestros caracteres latinos, tales como: tildes, signos de exclamación e interrogación en la apertura, letra ñ ... para caracteres codificados con 1 byte. Esto hacía necesario usar 2 bytes para codificar los caracteres latinos, ya que con 1 byte los caracteres incluidos son los de US-ASCII, subconjunto con un total de 128 caracteres correspondientes a las primeras posiciones de la tabla ASCII (American Standard Code for Information Interchange).
UTF-8 es un formato de codificación de caracteres Unicode e ISO-10646. La necesidad de usar 2 bytes para codificar caracteres latinos hace que la codificación en términos de consumo de espacio sea mayor, siendo necesario usar el doble de espacio (16 bits) si estamos codificando en algún idioma con caracteres latinos. A tal efecto se creó ISO-8859 y la derivación concreta ISO-8859-1 que es la norma de la ISO que define la codificación del alfabeto latino, incluyendo los diacríticos (como letras acentuadas, ñ, ç), y letras especiales (como ß, Ø). Esta codificación permite que dichos caracteres latinos se codifiquen en 8 bits, permitiendo la codificación del rango de los 128 primeros caracteres de la tabla ASCII y otros 128 caracteres más para lo que se denomina el conjunto de códigos extendidos de la tabla extendida ASCII. Puedes echarle un ojo a dicha tabla en:
Esta introducción que espero que haya servido para aclarar ciertos conceptos, sirve como base para la segunda parte que paso a explicar en las siguientes líneas.
Una forma habitual de pasar información en peticiones HTTP, es mediante el uso de encolado de parámetros en la URL (Uniform Resource Locator). Esto nos permite comunicarnos con APIs de otros servicios y a la vez es la base de las APIs RESTful como la que presentaba en la entrada "Linkero – Creación de APIs RESTful en Python".
Obviamente de nuevo tenemos una especificación para codificar las URLs que es la RFC-1738 de 1994 creada por Tim Berners-Lee, el inventor de World Wide Web. Dicha especificación define que sólo un reducido conjunto de caracteres puede usarse en las URLs, los cuales son:
A to Z (ABCDEFGHIJKLMNOPQRSTUVWXYZ)
a to z (abcdefghijklmnopqrstuvwxyz)
0 to 9 (0123456789)
$ (Dollar Sign)
- (Hyphen / Dash)
_ (Underscore)
. (Period)
+ (Plus sign)
! (Exclamation / Bang)
* (Asterisk / Star)
' (Single Quote)
( (Open Bracket)
) (Closing Bracket)
Para mapear el amplio rango de caracteres utilizados en todo el mundo en los 60 caracteres permitidos en una URL, se utiliza un proceso estándar de dos pasos:
Conversión de la cadena de caracteres, en una secuencia de bytes utilizando la codificación UTF-8.
Conversión de cada byte que no sea una letra o dígito ASCII a% HH, donde HH es el valor hexadecimal del byte.
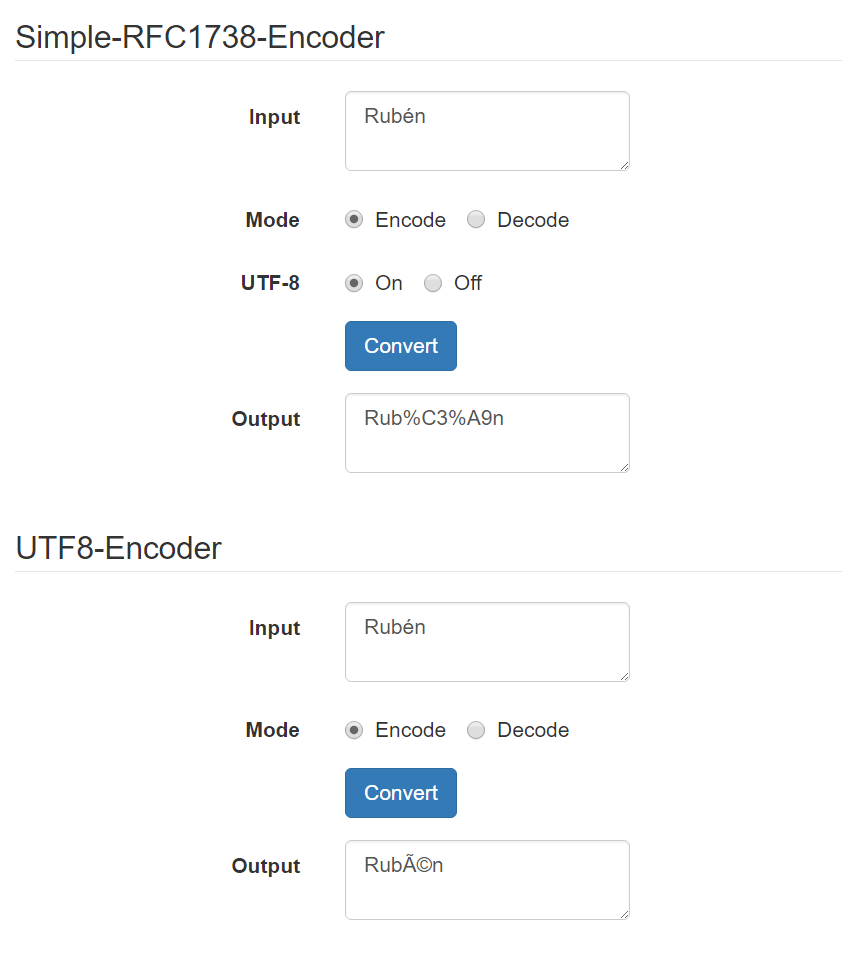
Por ejemplo, la cadena: "Rubén", sería codificada como: "Rub%C3%A9n"
El uso de UTF-8 nos obliga siempre a codificar dos veces, mientras que si se asume la codificación ISO-8859, sólo es necesario aplicar la RFC-1738. Veis por donde voy, ¿no? UTF-8 es un estándar que nos penaliza por no ceñirse nuestra grafía de las letras de nuestro alfabeto al conjunto de caracteres ingleses. A pesar de que podamos codificarlo luego de nuevo, se antoja un paso prescindible si directamente se asume ISO-8859 en cualquiera de sus variantes como base de codificación de los caracteres. En mi caso la ISO-8859-1. De esta forma la codificación con RFC-1738 queda con un único valor hexadecimal (perteneciente a la tabla ASCII extendida) para los caracteres ilegibles codificados con UTF-8. Esto además genera URLs más cortas al no tener que usar dos conjuntos de hexadecimales para un único caracter. Por ejemplo, la cadena: "Rubén", sería codificada como: "Rub%E9n".
Esta problemática me llevó a desarrollar Simple RFC1738 Encoder, al cual podéis acceder a su código desde la dirección del proyecto:
En la demo se pueden probar los distintos ejemplos de codificación presentados durante la entrada como son la codificación UTF-8 y la codificación RFC-1738 con o sin UTF-8 como codificación base. Podéis comprobar los resultados con las tablas facilitadas en el README del proyecto:
El proyecto Simple RFC1738 Encoder pretende ofrecer la capacidad de codificar las URLs usando RFC-1738 pero sin la necesidad de codificar con UTF-8 como base, pudiendo usar cualquier otra codificación como las recogidas en ISO-8859.
Uno de los problemas de desarrollar en PHP, es que se interpreta en el lado del servidor y lo que devuelve es la información procesada de la lógica de PHP. Esto nos lleva a la problemática de que es poco útil inundar de trazas de PHP que escriban en el HTML resultante de vuelta, los estados concretos de las variables procesadas durante la ejecución de la lógica programada.
Esto nos obliga a poner algún tipo de servicio de depuración que nos interrumpa la ejecución del intérprete de PHP y nos mande la información del estado de ejecución de cada punto de ruptura o de parada (breakpoint) que queramos añadir.
Uno de los frameworks de depuración más extendidos es XDebug, que además de ofrecer capacidades de depuración (debugging) también ofrece características de análisis de rendimiento (profiling). Este framework se integra muy bien con todos las soluciones de servidor PHP, como es mi caso concreto de XAMPP y mi entorno de desarrollo integradoNetbeans.
Para integrarlo lo primero que tenemos que hacer es localizar el fichero de configuración "php.ini" que contiene la información de configuración del intérprete de PHP que se encuentra en el directorio "xampp/php". Abrimos el fichero con un editor de texto cualquiera y buscamos la existencia de "[XDebug]" y descomentamos las siguiente líneas quitando el punto y coma de delante de cada línea para conseguir las siguiente configuración:
En el caso de no estar todas las líneas añade las que falten y si no encuentras nada que te referencie a XDebug, añádelo. En las últimas versiones de XAMPP sigue estando incluido XDebug, pero no hay rastro de él en el fichero de configuración. No obstante comprueba que existe en el directorio "xampp/php/ext" la libería dinámica "php_xdebug.dll".
Si alguno le echa un ojo al resto del fichero "php.ini", se dará cuenta que existen un apartado de extensiones dinámicas (Dynamic Extensions), donde se referencian otras librerías dinámicas del directorio "xampp/php/ext", cargadas con "extension=", en vez de "zend_extension=". Esto es debido a que se carga usando el motor Zend. Si no lo respetáis, no os funcionará a pesar de que PHP os lo reconozca.
Para que la configuración tenga efecto guardamos el fichero y reniniciamos Apache si estaba ya funcionando. Si todo está correcto, entrando en la siguientes direcciones:
... deberíamos poder encontrar XDebug y poder ver toda la configuración.
Ahora vayamos a Netbeans, quien por defecto ya viene con XDebug preconfigurado. En "Herramientas-->Opciones-->PHP-->Debugging", comprobamos que "Debugger Port" sea el 9000 (el que configuramos en el fichero php.ini) y desmarcamos, si lo estuviera, la opción "Stop at First Line" para que no entre en modo depuración en la primera línea del proyecto, sino cuando encuentra un breakpoint.
Ahora si marcamos en cualquier parte del código con un breakpoint y lanzamos el proyecto en modo depuración , la ejecución parará en el breakpoint marcado, pudiendo continuar la ejecución paso a paso si lo necesitásemos, supervisando la lógica y valores tomados durante la ejecución.
Como habéis podido ver, el depurado XDebug configurado en XAMPP e integrado con Netbeans, resulta de los más útil, dotándonos de una herramienta de depuración perfecta para trabajar en nuestros proyectos de PHP.
Habitualmente se genera código que funciona, y que no por ello quiere decir que esté bien codificado. Cuando me refiero a bien codificado, me refiero a que no existan secciones de código que no se usan, que los comportamientos del código sean deterministas, que se codifique evitando generar brechas de seguridad, que cumpla unas reglas de codificación que aseguren una buena comprensión del código, que se genere documentación del código... Por ello, algo que funcione no es sinónimo de que esté bien codificado (simplemente funciona).
En mi día a día suelo utilizar habitualmente Python y el estupendo IDEPyCharm para desarrollar mi trabajo. También tengo que orientar a otras personas que se están formando en este lenguaje, y eso conlleva una supervisión del código generado, no en el sentido de revisión que asegure la funcionalidad, sino el de asegurar una serie de buenas praxis en la codificación. Se trata del paso anterior a cualquier tipo de Testing.
Hablando con un compañero surgió el tema de asegurar unas buenas praxis para el lenguaje Python de personas interinas en la empresa que acaban de empezar, que desarrollan sus prácticas, su proyecto PFG (Proyecto Fin de Grado) o PFM (Proyecto Fin de Master). Estas buenas praxis no son otra cosa que la extensión del Zen de Python promulgado por Tim Peters:
Bello es mejor que feo.
Explícito es mejor que implícito.
Simple es mejor que complejo.
Complejo es mejor que complicado.
Plano es mejor que anidado.
Disperso es mejor que denso.
La legibilidad cuenta.
Los casos especiales no son tan especiales como para quebrantar las reglas.
Aunque lo práctico gana a la pureza.
Los errores nunca deberían dejarse pasar silenciosamente.
A menos que hayan sido silenciados explícitamente.
Frente a la ambigüedad, rechaza la tentación de adivinar.
Debería haber una -y preferiblemente sólo una- manera obvia de hacerlo.
Aunque esa manera puede no ser obvia al principio a menos que usted sea holandés.
Ahora es mejor que nunca.
Aunque nunca es a menudo mejor que ya mismo.
Si la implementación es difícil de explicar, es una mala idea.
Si la implementación es fácil de explicar, puede que sea una buena idea.
Los espacios de nombres (namespaces) son una gran idea ¡Hagamos más de esas cosas!
Si el código cumple con estas directrices se dice que es código "pythonico". Esta filosofía ha hecho que Python lleve en su ADN esa características de legibilidad y transparencia.
Toda esta introducción nos lleva a las Python Enhancement Proposal (PEP) como formalismo de estas buenas praxis, siendo el Zen de Python la PEP20. Pero la pregunta es: ¿cómo me aseguro cumplir estas buenas praxis?, ¿y qué otros las cumplan?, ¿y qué además la forma de evaluarlas sea la misma? La respuesta es un revisor automático como es el caso de PyLint, que asegura una codificación estandarizada alineada con lo que se entiende con un código pythonico, la corrección de errores, la detección de código duplicado o que no se usa... en definitiva asegurar la buena praxis durante la codificación.
PyLint es un revisor automático ampliamente usado e integrado en otros servicios de mayor envergadura como es el caso de Codacy. Sitio de donde tomé la idea de coger un revisor local que se pudiese ejecutar desde el propio equipo, pero que a la vez se pudiese configurar de manera sencilla en el proyecto, y por supuesto integrarlo en mi IDE PyCharm.
Como primer paso, lo que hice fue instalarlo de manera sencilla con el comando "pip":
pip install pylint
Lo primero tras instalarlo fue hacer la prueba de ejecutarlo contra código que ya tenía evaluado por Codacy para poder comprobar lo estricto que era el revisor por defecto. Para mi mayor pena, el proyecto que arrojaba una calificación de B en Codacy, se quedaba en un 2.5 sobre 10. Inmediatamente me dí cuenta de que la vara de medir era extremadamente estricta por defecto, con lo que exporté los parámetros de revisión con los que Codacy revisaba mi código, ya que entendía que era una revisión más coherente.
Acto seguido revisé aquellas parametrizaciones que correspondían a PyLint y las migré a un fichero "pylintrc" que puede albergar la información de configuración de PyLint. Para ello ejecuté el siguiente comando, obteniendo la plantilla del "pylintrc":
pylint --generate-rcfile > .pylintrc
Una vez obtenida la plantilla del fichero de configuración, posteriormente modifiqué la sección "MESSAGES CONTROL" para deshabilitar todas las reglas de revisión por defecto y añadir las que yo deseaba, y que además coincidían con las de revisión en Codacy.
La serie de códigos que añado son una normalización de distintas reglas aplicables en PyLint para revisar el código. Podéis disponer del fichero completo con las reglas desde el siguiente Gist:
Con ese fichero "pylintrc" ya es posible portar la configuración para el revisor PyLint en cualquier proyecto. Sólo debemos añadirlo a la raíz de cualquier proyecto Python.
Anteriormente he comentado que uso PyCharm como IDE, y claro está, que ejecutar esta herramienta por línea de comandos, no resulta lo ideal. No os preocupéis porque existe una integración bastante directa de PyLint en PyCharm. Para ello solo tenéis que ir a File --> Settings --> Tools --> External Tools en vuestro PyCharm y añadir la siguiente configuración haciendo click en el símbolo + de color verde:
Poned el nombre y una descripción para la herramienta y desmarcad "Synchronize files after execution". En "Program" buscad dentro de la carpeta de instalación de Python en el subdirectorio Scripts el ejecutable "pylint.exe", si sois usuarios Windows, y en el directorio "/usr/bin" si sois usuarios de Linux.
Los parámetros que se introducen son la ubicación del fichero de configuración de PyLint (que debiera estar en la raíz del proyecto) y la macro que corresponde al fichero o carpeta que analizaríamos con PyLint. En "Working directory" ponemos la macro que apunta al directorio del proyecto correspondiente al fichero o carpeta que analicemos. Guardamos y para probarlo basta con ir a la raíz del proyecto y ejecutar PyLint con el botón derecho External Tools --> PyLint.
Como podéis ver, con esta integración tenéis una excelente herramienta que mejorará (si hacéis caso a sus reportes) vuestro código, generando un código mucho más pythonico.