
GitHub es una plataforma increíble que hace todo más fácil en la gestión de proyectos versionados con Git. Una de las grandes cosas que tiene GitHub es la de hacer un fork, que es una copia vinculada al repositorio original bajo tu completa administración.
Esta copia no es completa, puesto que no incluye algunas cosas relevantes como la Wiki, que es donde se documenta la información del proyecto. A efectos prácticos la Wiki se comporta exactamente igual que un repositorio gestionado con Git y que se compuesto por ficheros markdown. A mi juicio, el hacer un fork del proyecto debería incluir tanto el repositorio principal del proyecto como el repositorio Wiki del mismo. Quizás en un futuro no muy lejano lo veamos, quién sabe... 😉
Cuando hacemos un fork de un proyecto y vamos a la Wiki nos anima a crear nuestra primera página:
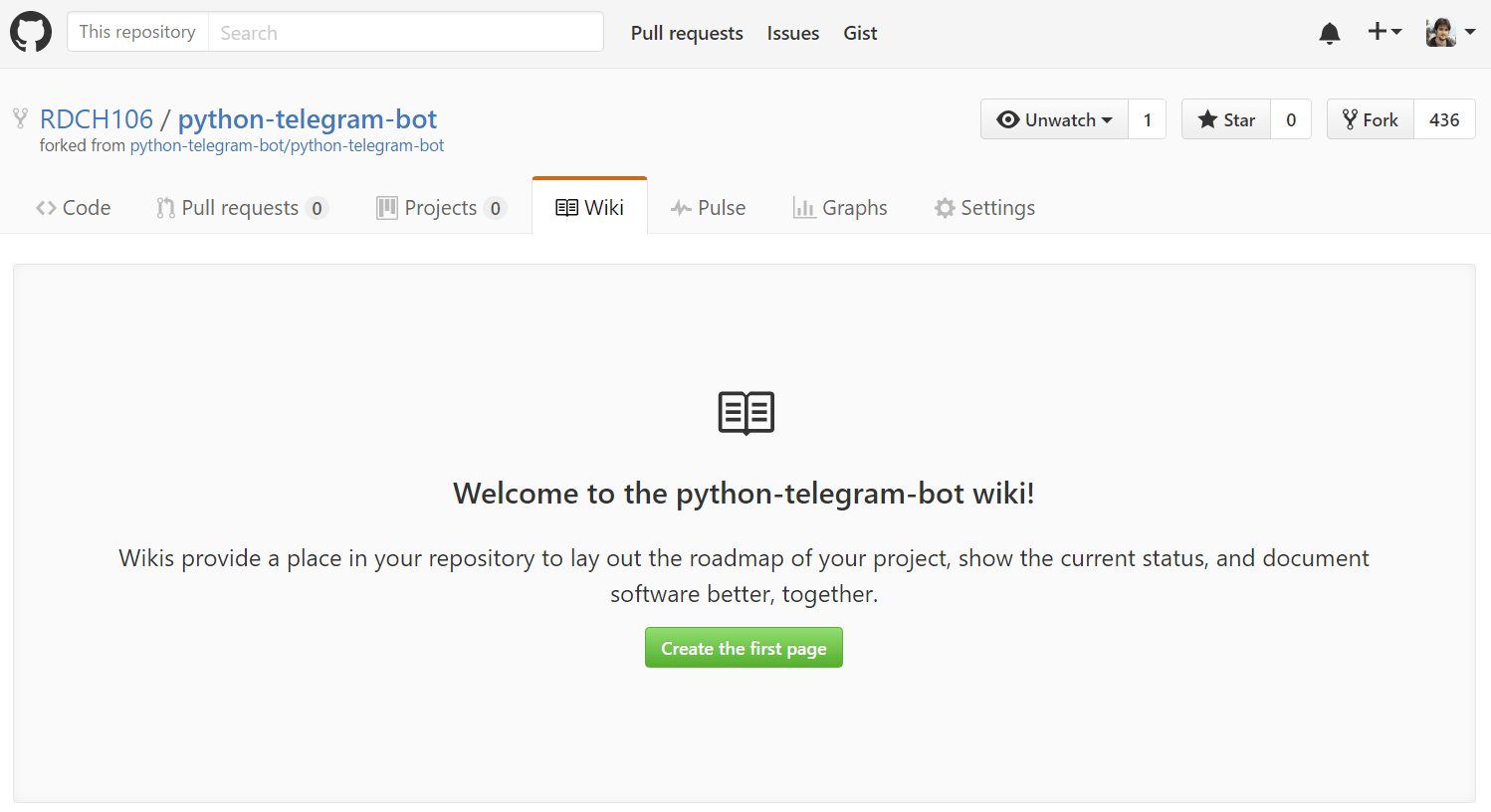
Aunque pudiera parece que al haber una sección Wiki, existe un repositorio, esto no es así. Hasta que no creemos la primera página que suele denominarse "Home", el repositorio de la Wiki no existirá. Si se intenta hacer push al repositorio, seguramente os arroje un error como este:
remote error: access denied or repository not exported
Esto es un error de falta de permisos que puede hacerte perder bastante el tiempo, si no caes en la cuenta que el error no es por falta de permisos, sino por la ausencia de repositorio.
Una vez aclarado el tema basta con darle a "Create the first page":
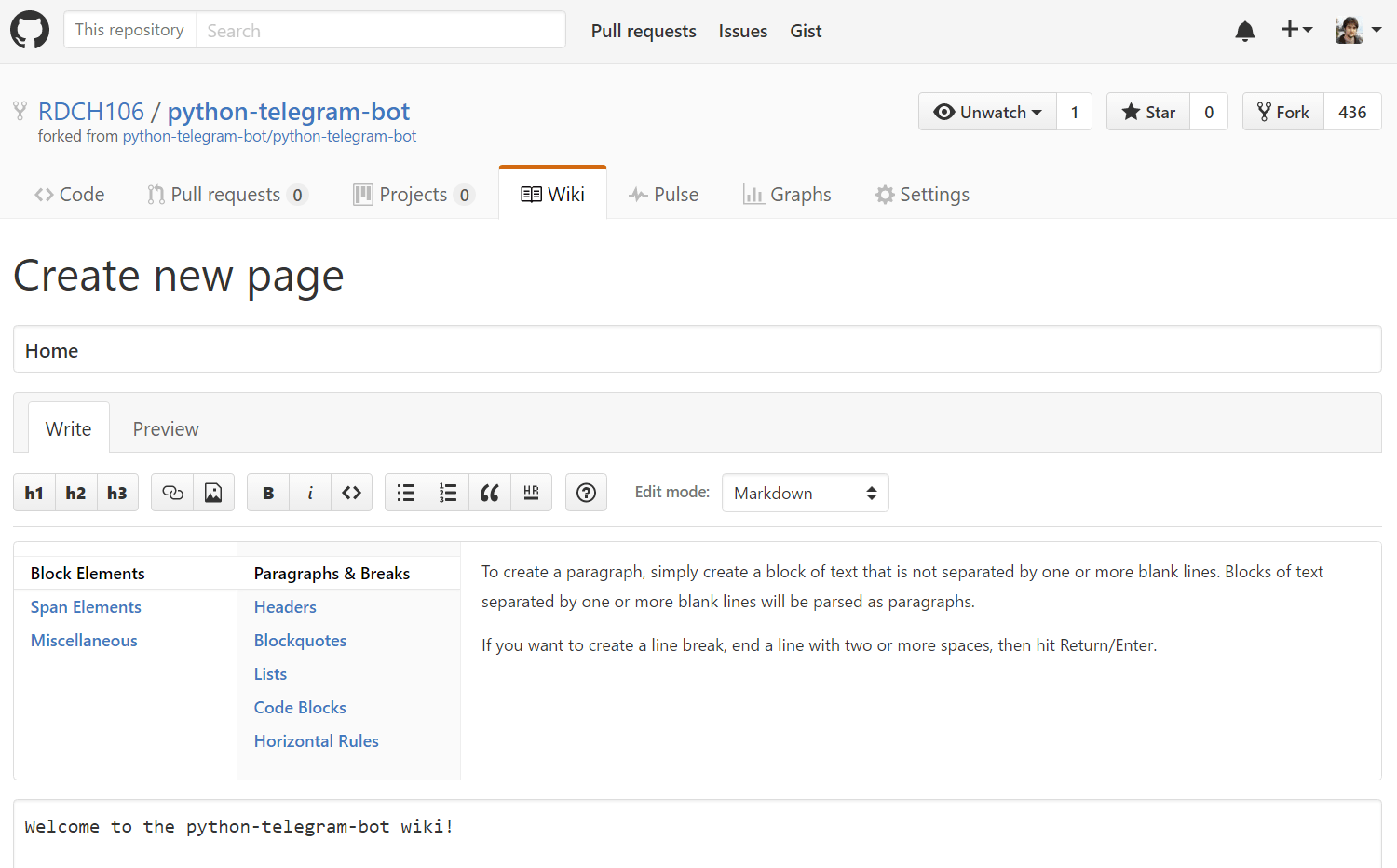
Dejaremos tal cual está todo porque sobrescribiremos el contenido, sólo lo hacemos para que se cree el repositorio de la Wiki. Avanzamos hacia abajo y le damos a "Save Page".

Ahora tenemos nuestra Wiki inicializada con su reapositorio activo:
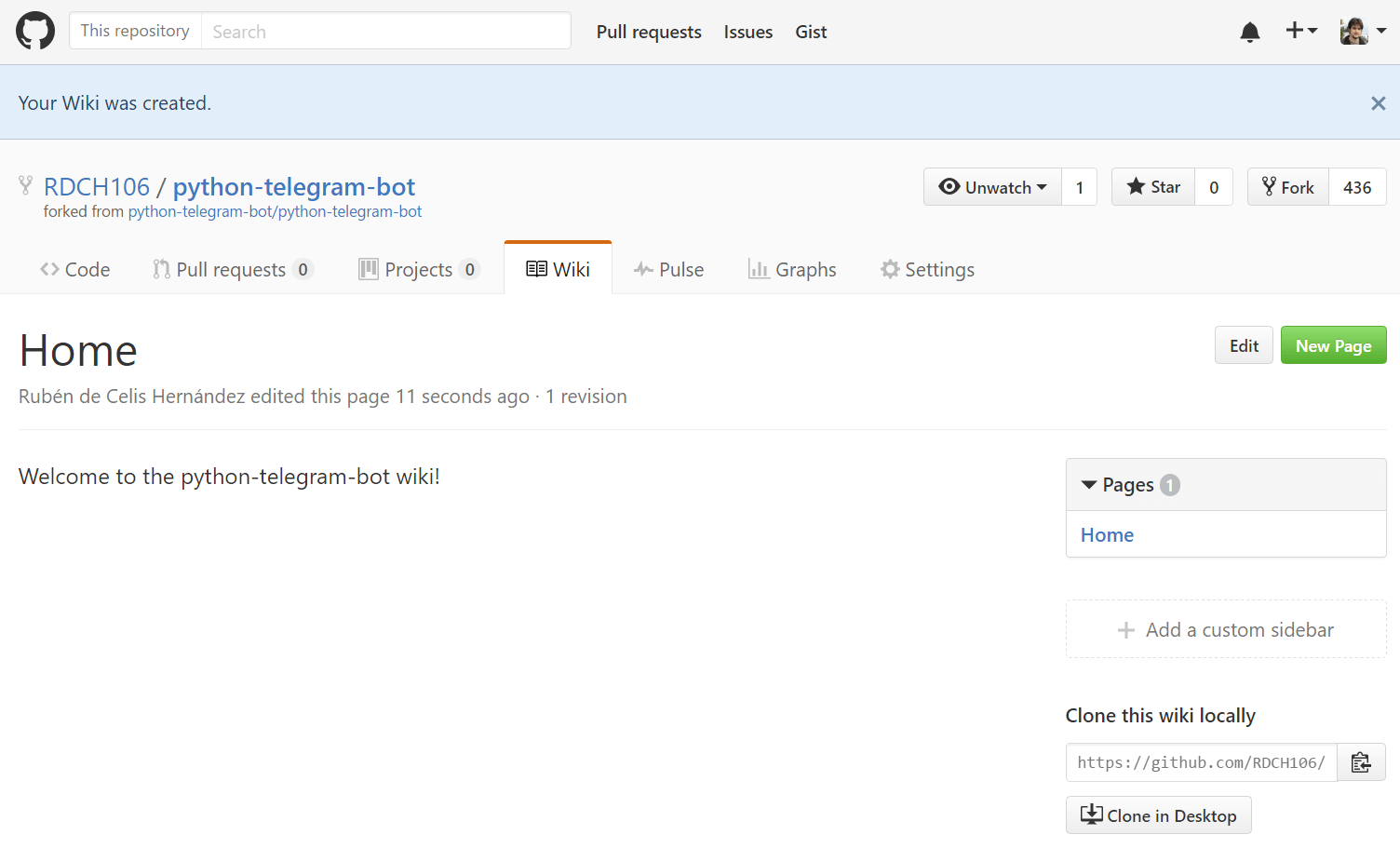
Una vez llegados a este punto hay dos formas de hacer las cosas. En la primera de ellas, puede que la más fácil, sea hacer un clone del repositorio Wiki del original, hacer otro clone de nuestro repositorio Wiki en el fork, y copiar todos los archivos del repositorio Wiki original al de nuestro fork. De esta forma al hacer commit y luego push en nuestro repositorio, tendremos la Wiki. El mayor problema de este método es que primero vamos a tener un commit inicial y que luego vamos a tener un segundo con toda la Wiki. Esto nos hace perder el versionado que traía consigo el repositorio Wiki del proyecto original.
Otra forma más óptima que nos permite mantener el versionado del repositorio Wiki del proyecto original, es el que paso a describiros a continuación de manera detallada.
Primero hacemos un "git clone" del repositorio Wiki del proyecto original:
git clone url_wiki_original
Una vez clonado añadimos nuestra Wiki del fork como remoto con "git remote" (no usar como "remote_name" el nombre de origin):
git remote add remote_name url_wiki_fork
Ahora con el nuevo remoto añadido podemos hacer un "git push" forzado:
git push remote_name master --force
El parámetro "remote_name" es el mismo que cuando hemos añadido el remote en el paso anterior (el de la Wiki de nuestro fork), la rama es "master" (rama principal pero que puede ser cualquier otra que se quiera), y el parámetro "--force" que sirve para sobrescribir la referencia que tuviese anteriormente de la rama y sobrescribir por la que se manda (cuidado con este parámetro que puede resultar peligroso).
El resultado como podéis ver es la de nuestra Wiki actualizada con la del proyecto original:
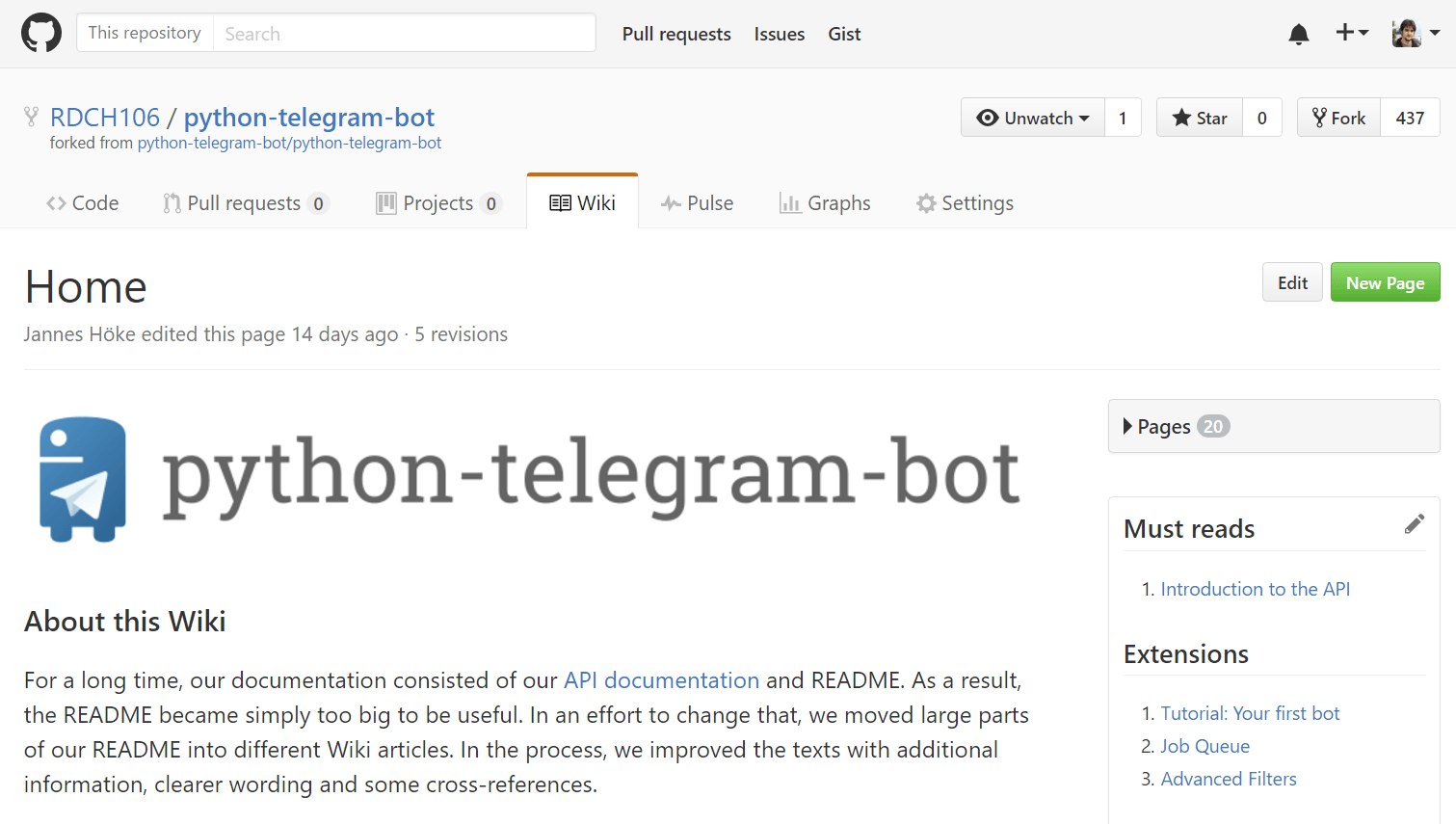
Ahora queda un minúsculo detalle y es el "HEAD", la referencia que indica cual es remote y rama por defecto. Por defecto apunta a "origin/master", que es el remoto de donde se hace el clone. Por esta razón hay que cambiar el "HEAD" para que apunte a nuestro fork como origin y a nuestra rama master. La manera más sencilla es coger y hacernos un "git clone" del repositorio Wiki de nuestro fork y todo listo. 😉
Con este procedimiento ya podéis incluir en vuestros forks la tan preciada y a veces escasa documentación que se adjunta en los repositorios de los proyectos.