La Informática e Internet es una piña de estándares que muchas veces a los desarrolladores nos son transparentes. Esto provoca que habitualmente no nos formulemos la pregunta de cómo se codifica, se procesa y se manda una dato, ya que existen funciones de alto nivel que nos resuelven dicha problemática o simplemente se realiza de manera transparente al desarrollador mediante un Framework o Librería.
¿Alguna vez te has preguntado cómo se codifican los caracteres que escribes? La verdad es que esto de la informática nació en los Estados Unidos y su Silicon Valley. Esto hace obvio que las codificaciones se pensaron para el inglés.
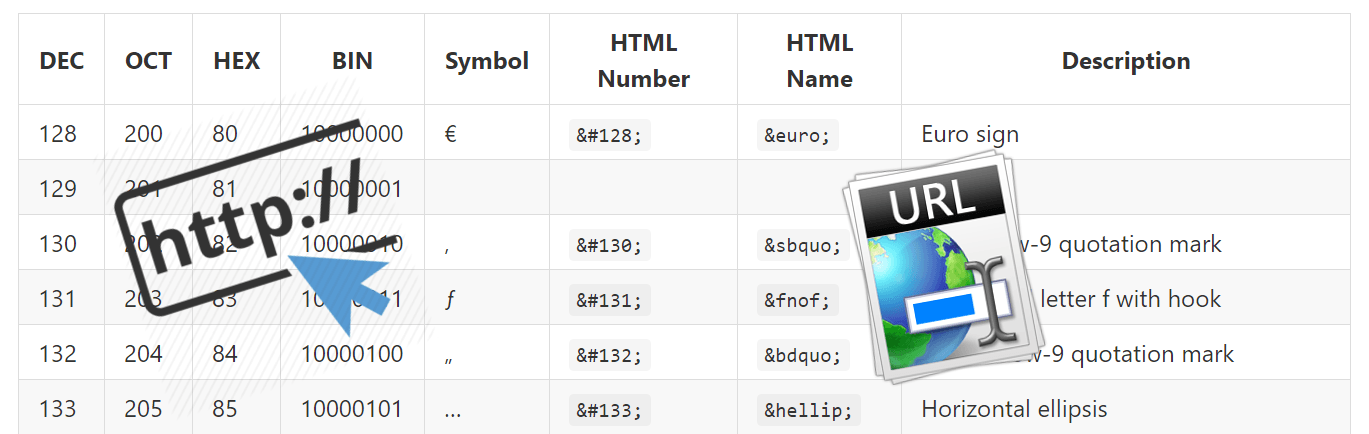
Con el tiempo la informática se extendió hasta su uso normalizado que tenemos hoy en día. El problema que tuvimos los de habla latina era que la codificación de base era UTF-8 y no incluía nuestros caracteres latinos, tales como: tildes, signos de exclamación e interrogación en la apertura, letra ñ ... para caracteres codificados con 1 byte. Esto hacía necesario usar 2 bytes para codificar los caracteres latinos, ya que con 1 byte los caracteres incluidos son los de US-ASCII, subconjunto con un total de 128 caracteres correspondientes a las primeras posiciones de la tabla ASCII (American Standard Code for Information Interchange).

UTF-8 es un formato de codificación de caracteres Unicode e ISO-10646. La necesidad de usar 2 bytes para codificar caracteres latinos hace que la codificación en términos de consumo de espacio sea mayor, siendo necesario usar el doble de espacio (16 bits) si estamos codificando en algún idioma con caracteres latinos. A tal efecto se creó ISO-8859 y la derivación concreta ISO-8859-1 que es la norma de la ISO que define la codificación del alfabeto latino, incluyendo los diacríticos (como letras acentuadas, ñ, ç), y letras especiales (como ß, Ø). Esta codificación permite que dichos caracteres latinos se codifiquen en 8 bits, permitiendo la codificación del rango de los 128 primeros caracteres de la tabla ASCII y otros 128 caracteres más para lo que se denomina el conjunto de códigos extendidos de la tabla extendida ASCII. Puedes echarle un ojo a dicha tabla en:
https://github.com/RDCH106/Simple-RFC1738-Encoder#ascii-code---the-extended-ascii-table
Esta introducción que espero que haya servido para aclarar ciertos conceptos, sirve como base para la segunda parte que paso a explicar en las siguientes líneas.
Una forma habitual de pasar información en peticiones HTTP, es mediante el uso de encolado de parámetros en la URL (Uniform Resource Locator). Esto nos permite comunicarnos con APIs de otros servicios y a la vez es la base de las APIs RESTful como la que presentaba en la entrada "Linkero – Creación de APIs RESTful en Python".
Obviamente de nuevo tenemos una especificación para codificar las URLs que es la RFC-1738 de 1994 creada por Tim Berners-Lee, el inventor de World Wide Web. Dicha especificación define que sólo un reducido conjunto de caracteres puede usarse en las URLs, los cuales son:
- A to Z (ABCDEFGHIJKLMNOPQRSTUVWXYZ)
- a to z (abcdefghijklmnopqrstuvwxyz)
- 0 to 9 (0123456789)
- $ (Dollar Sign)
- - (Hyphen / Dash)
- _ (Underscore)
- . (Period)
- + (Plus sign)
- ! (Exclamation / Bang)
- * (Asterisk / Star)
- ' (Single Quote)
- ( (Open Bracket)
- ) (Closing Bracket)
Para mapear el amplio rango de caracteres utilizados en todo el mundo en los 60 caracteres permitidos en una URL, se utiliza un proceso estándar de dos pasos:
- Conversión de la cadena de caracteres, en una secuencia de bytes utilizando la codificación UTF-8.
- Conversión de cada byte que no sea una letra o dígito ASCII a% HH, donde HH es el valor hexadecimal del byte.
Por ejemplo, la cadena: "Rubén", sería codificada como: "Rub%C3%A9n"
Este es el proceso que de manera estándar se usa y que puedes encontrar en funciones como encodeURI en Javascript o urlencode en PHP. Pero esto no quiere decir que no puedas usar ISO-8859 como codificación base y luego codificar la URL con RFC-1738, consiguiendo de esta forma trabajar sobre una base de caracteres que permite ciertos caracteres, que aunque se puedan codificar en UTF-8, resultan ilegibles. Por ejemplo, la cadena: "Rubén", sería codificada como: "Rubén". No se entiende, ¿verdad?
El uso de UTF-8 nos obliga siempre a codificar dos veces, mientras que si se asume la codificación ISO-8859, sólo es necesario aplicar la RFC-1738. Veis por donde voy, ¿no? UTF-8 es un estándar que nos penaliza por no ceñirse nuestra grafía de las letras de nuestro alfabeto al conjunto de caracteres ingleses. A pesar de que podamos codificarlo luego de nuevo, se antoja un paso prescindible si directamente se asume ISO-8859 en cualquiera de sus variantes como base de codificación de los caracteres. En mi caso la ISO-8859-1. De esta forma la codificación con RFC-1738 queda con un único valor hexadecimal (perteneciente a la tabla ASCII extendida) para los caracteres ilegibles codificados con UTF-8. Esto además genera URLs más cortas al no tener que usar dos conjuntos de hexadecimales para un único caracter. Por ejemplo, la cadena: "Rubén", sería codificada como: "Rub%E9n".
Esta problemática me llevó a desarrollar Simple RFC1738 Encoder, al cual podéis acceder a su código desde la dirección del proyecto:
https://github.com/RDCH106/Simple-RFC1738-Encoder
En el proyecto se explica de manera más resumida lo presentado en esta entrada y se ofrece la posibilidad de probar la librería desde:
https://rawgit.com/RDCH106/Simple-RFC1738-Encoder/master/demo.html
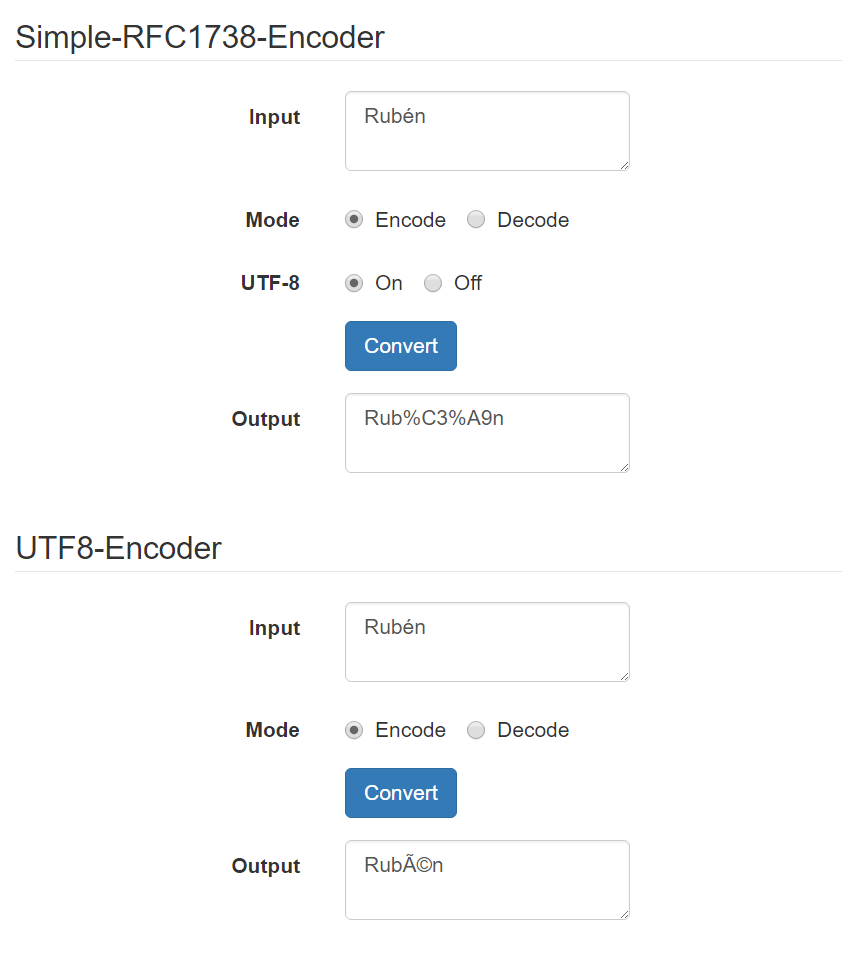
En la demo se pueden probar los distintos ejemplos de codificación presentados durante la entrada como son la codificación UTF-8 y la codificación RFC-1738 con o sin UTF-8 como codificación base. Podéis comprobar los resultados con las tablas facilitadas en el README del proyecto:
https://github.com/RDCH106/Simple-RFC1738-Encoder/blob/master/README.md
El proyecto Simple RFC1738 Encoder pretende ofrecer la capacidad de codificar las URLs usando RFC-1738 pero sin la necesidad de codificar con UTF-8 como base, pudiendo usar cualquier otra codificación como las recogidas en ISO-8859.