
En esta ocasión tengo el gusto de presentar a Jorge, un excelente compañero de trabajo y un grandísimo profesional. En su día a día siempre anda buscando la mejor forma de hacer las cosas y en esta ocasión nos trae un detallado tutorial de Integración Continua, ámbito en el que recientemente se ha sumergido, y del que hoy nos presenta unas pildoritas de sabiduría y buen hacer.
GitHub, con todo el revuelo que ha provocado la compra por parte de Microsoft, es uno de los mayores repositorios de código que existen, y el mayor de código libre. Dispone de múltiples herramientas que ayudan al desarrollo de aplicaciones y testeo de aplicaciones que en muchos casos no son explotadas, lo cual es una lástima ya que son gratuitas (siempre que tu repositorio sea público) y aportan una gran ayuda.
En esta entrada vamos a hablar sobre una de esas herramientas llamada AppVeyor, ¿y que es AppVeyor? Es una herramienta de integración continua que permite realizar compilaciones, ejecutar teses, y publicar binarios, todo ello con unos pocos clicks gracias a su alta integración en GitHub (y encima gratuito si tu repositorio es público).
Llegados a este punto, se puede pensar, ¿qué me puede aportar a mi todo eso? La respuesta es sencilla, si tienes algún repositorio en el que colaboras con más gente, siempre sabréis que los cambios van a compilar, y en el caso de que tengáis test unitarios, que los ha pasado, y además de todo eso, publicar las "release" si así lo queréis. Vale, ahora pensarás, yo soy un desarrollador independiente, que no comparte repositorios, y tampoco me preocupo en sacar ninguna "release", ¿en qué puede ayudarme a mi? Fácil, puedes configurar diferentes "build" para diferentes entornos, y probar que tu código es perfectamente funcional en varias plataformas y versiones sin necesitar disponer de esas máquinas para compilar en ellas.
Compilación
¿Te he convencido? Pues vamos a ver como podemos configurar esta herramienta para nuestro repositorio. Lo primero es registrarnos en su web (algo muy fácil usando nuestra cuenta de GitHub).
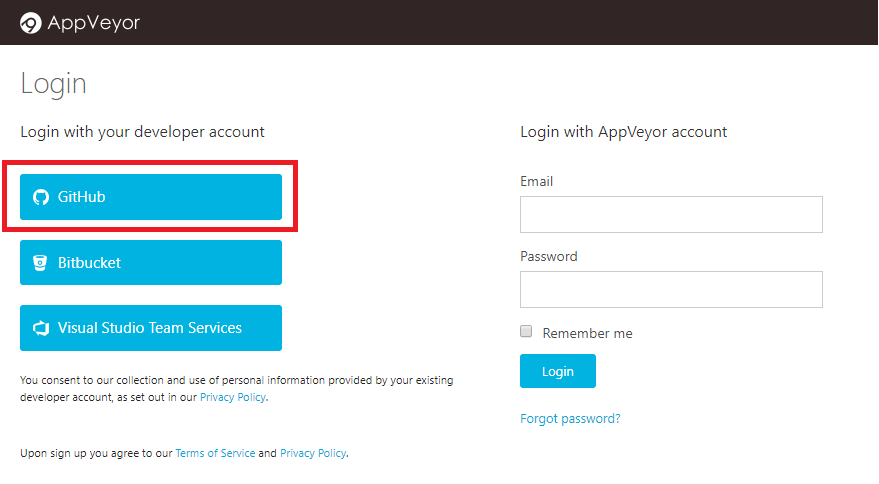
Con sólo eso, ya estamos registrados, y llegamos a nuestro "dashboard", que por el momento estará vacío, pero vamos a solucionarlo pulsando en "NEW PROJECT" .

Para este ejemplo, he creado un repositorio en mi perfil llamado PostAppVeyor, el cual aparece automáticamente, y simplemente hay que pulsar en "ADD".

Ya tenemos nuestra integración lista, aunque de momento no haya hecho nada, veamos qué pasa si pulsamos en "NEW BUILD".
![]()
Pulsando esto, se lanzará una compilación que se puede seguir desde "LATEST BUILD".

Un detalle importante, es que al haber añadido AppVeyor al repositorio, se establecen automáticamente los WebHooks para notificar a GitHub los resultados, y si miramos el historial de commits del repositorio, se puede ver el resultado.
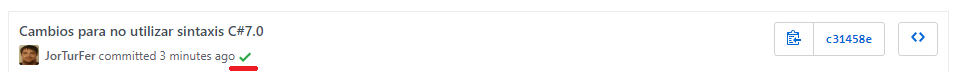
Esto también se aplica automáticamente para los "Pull Request", de modo que siempre se comprobarán las modificaciones que haya sobre el repositorio.
Test unitarios
Vale, el repositorio compila, ¿cómo añado los teses? Otra respuesta fácil, AppVeyor es capaz de detectarlos automáticamente. Añadamos un test al proyecto y veamos que pasa al "pushearlo" a GitHub. Automáticamente se inicia una compilación pero... ha fallado, ¿por qué?, si en Visual Studio pasaba el test sin problemas...

Vale, esto es debido a que los teses unitarios de Visual Studio, necesitan descargar paquetes NuGet. Vamos a solucionar esto yendo a la pestaña "SETTINGS" y al menu "Build". Hay que buscar "Before build script" para añadir un evento previo a la compilación, que haga un "nuget restore", tras esto, basta con pulsar en "Save" y ya estaría listo.
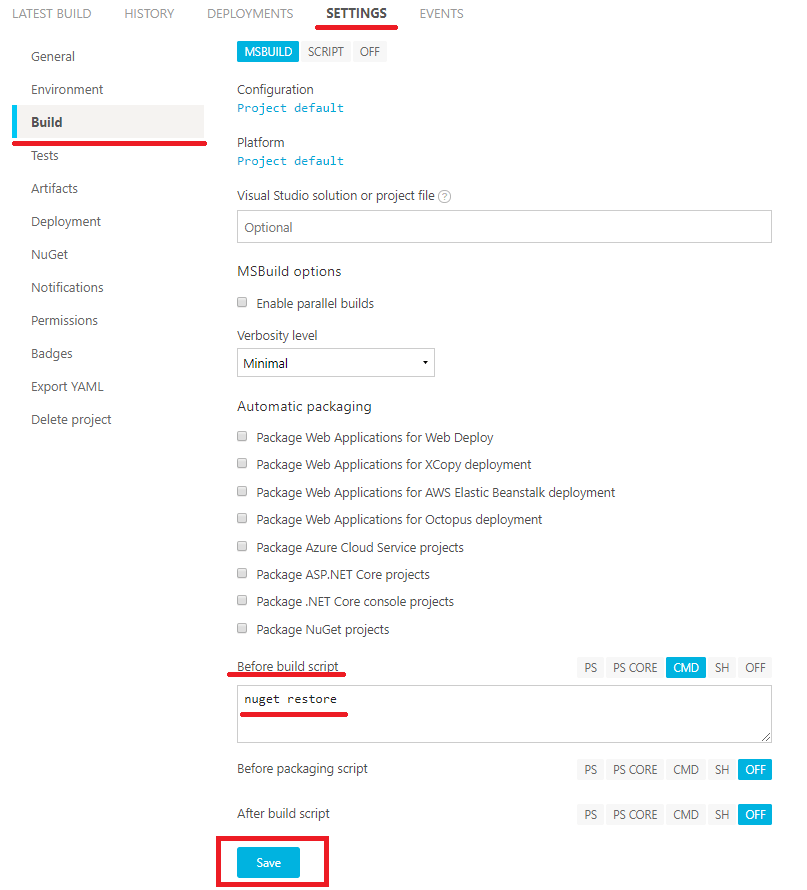
Ahora que tenemos todo lo necesario, vamos a volver a probar (Mediante el botón "RE-BUILD" del resultado que ha fallado) y ¡sopresa!, ya funciona correctamente.

Pero espera... a mi no me dice eso. Mis teses no se ejecutan, ¿qué pasa? Bueno, es posible que tu proyecto este hecho en un Visual Studio superior al que usa por defecto (2015), y el descubrimiento de teses unitarios no haya funcionado del todo bien, esto podemos solucionarlo rápidamente seleccionando la versión de Visual Studio que vamos a utilizar (en mi caso 2017). Volviendo a la pestaña "SETTINGS", pero esta vez en el menú "Environment", seleccionando Visual Studio 2017 y damos a "Save".


Veamos el resultado ahora pulsando en "RE-BUILD".... ¡¡¡Premio, nuestros teses ya se ejecutan!!!
Con todo lo que hemos hecho hasta ahora, tenemos un repositorio que comprueba automáticamente si el código compila correctamente, y ademas ejecuta los teses unitarios para comprobar que sigue cumpliendo con el funcionamiento esperado.
En la próxima entrada veremos cómo generar y publicar las "releases" a partir de nuestro código compilado y testeado.