
En esta segunda parte, Jorge nos amplía y completa un poco más la anterior entrada sobre la Integración Continua con AppVeyor, para mostrarnos cómo generar y publicar una release automáticamente.
Generación del artefacto
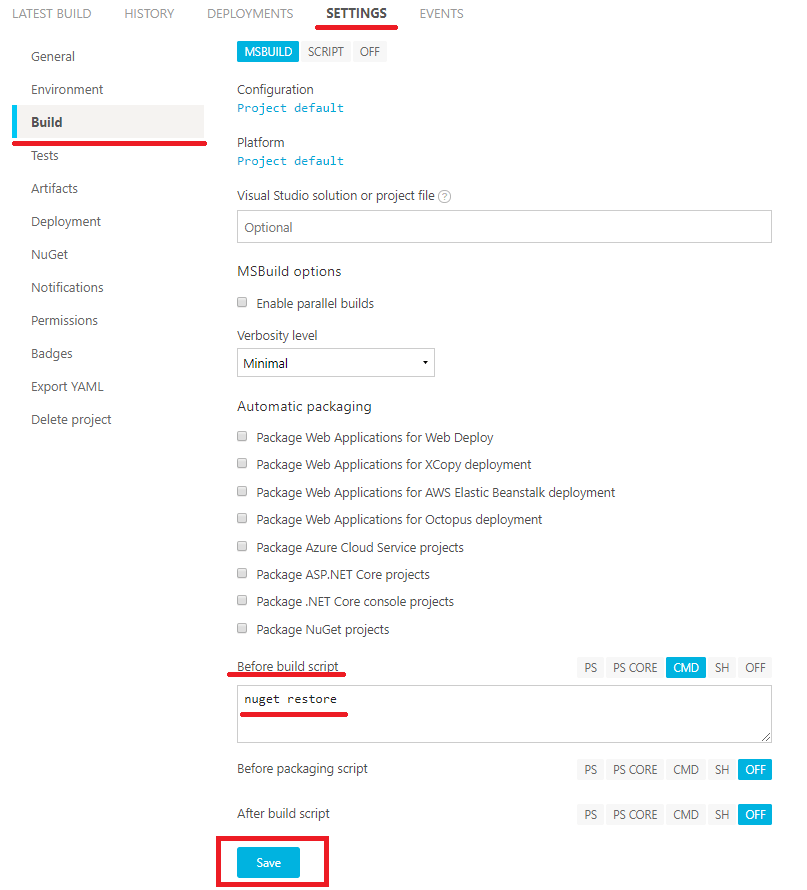
Lo primero que será necesario es configurar un "artifact", que sera lo que se haga "push" hacia GitHub, para ello, en la pestaña "SETTINGS" en el menú "Build", haremos que los resultados que nos interesen se añadan a un .zip, creando un "After build script", en el cual meteremos los binarios que nos interese. Previamente a eso, vamos a indicarle en la parte superior, que queremos que la compilación utilice "debug" y "release".

El script:
7z a PostAppVeyor_%configuration%.zip %APPVEYOR_BUILD_FOLDER%\%APPVEYOR_PROJECT_NAME%\bin\%configuration%\*.exe
Añadirá todos los .exe que haya en la carpeta al fichero que indicamos, en caso de necesitar añadir otros ficheros o librerías, se podría indicar cambiando el patrón de búsqueda o poniendo rutas absolutas.
Con esto, AppVeyor va a generar el .zip, ahora sólo queda hacer que sea público como resultado de la compilación. Para eso, en la pestaña "SETTINGS", en el menú "Artifacts", lo creamos mediante el botón "Add artifact".

Seleccionando el .zip que se ha generado mediante el script, se le pone un nombre con el cual publicarlo en AppVeyor (hay que tener en cuenta que AppVeyor borra todos estos archivos a los 6 meses).

Publicación del artefacto
Después de todo lo anterior, sólo nos queda publicar los binarios en el apartado de "Release" de GitHub cuando nos interese. Para ello, lo primero de todo, necesitamos generar un token en GitHub para AppVeyor. Esto se hace desde el perfil , en el apartado "Settings/Developer Settings/Personal Access Tokens" pulsando en "Generate new token".

Tras darle un nombre, los permisos que necesitamos asignarles son simplemente "public_repo" y pulsar en "Generate token".

Esto nos genera un código alfanumérico, que debemos copiar, ya que lo necesitaremos en AppVeyor para configurarlo.

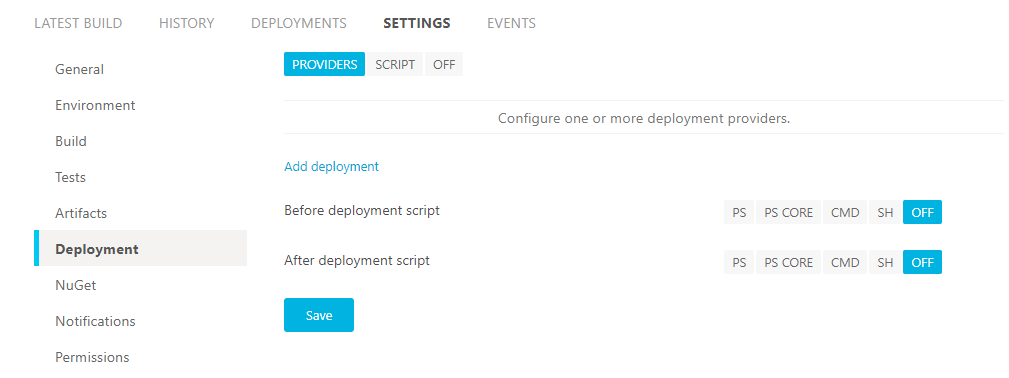
Una vez tenemos el token, nos vamos a AppVeyor y en la pestaña "SETTINGS" en el menú "Deployment", seleccionamos "Add deployment".
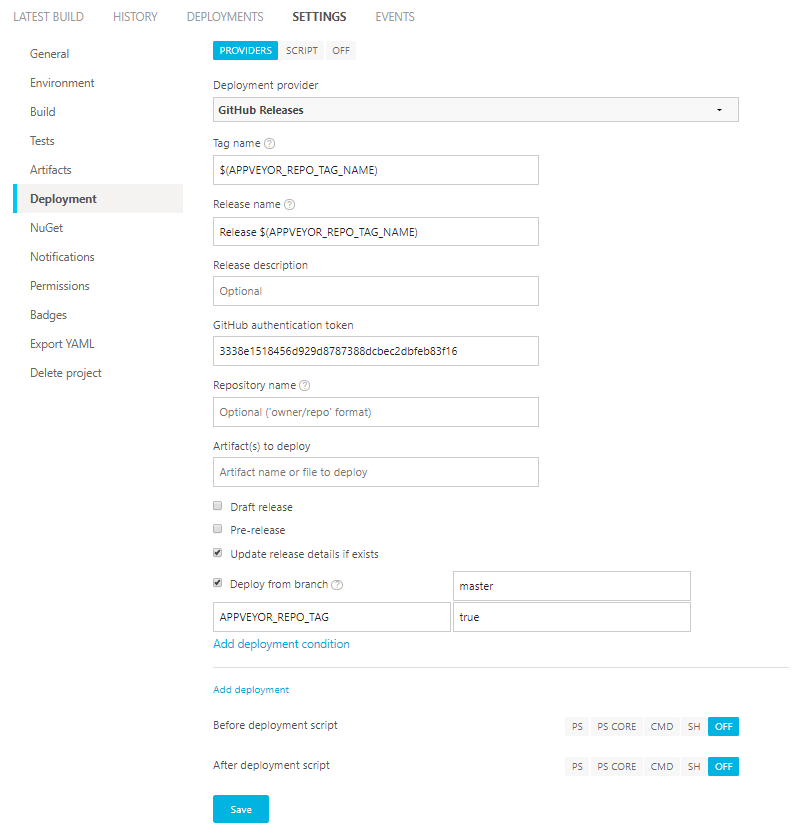
En el desplegable, hay que seleccionar "GitHub Releases". Cabe destacar que vamos a configurarlo para que sólo se publiquen como release los "Tags" del repositorio en la rama master. Para eso, vamos a configurar los parámetros de publicación que se ofrecen, teniendo especial cuidado en añadir una condición que sera "APPVEYOR_REPO_TAG" = true, para que sólo las etiquetas se suban a GitHub Release. Un ejemplo de como configurarlo seria el siguiente:
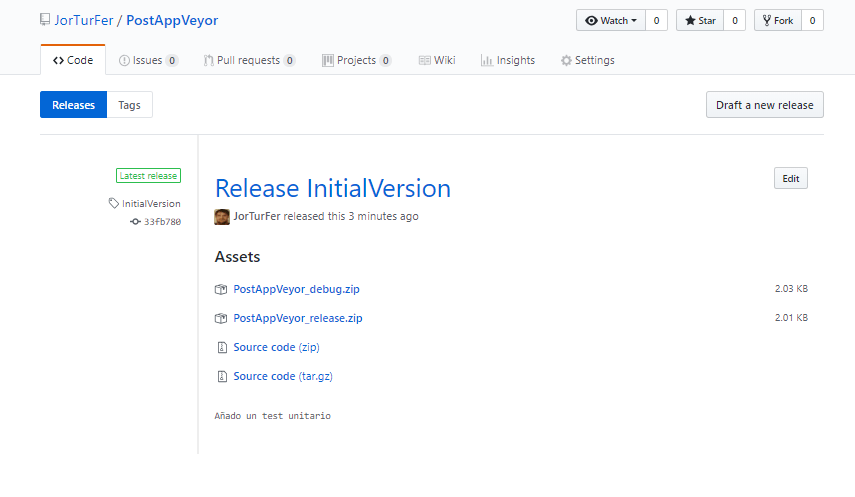
Una vez todo listo, solo nos queda crear un tag en nuestro proyecto, y pushear el tag a Github, esto iniciará el proceso, y cuando acabe, se podrá ver el resultado en el apartado "releases" del repositorio de GitHub.
Con esto queda cerrado el ciclo de despligue que junto a la entrada anterior sobre integración y testeo continuo, nos permite llevar nuestro código a cotas de calidad de desarrollo muy altas, preparando a su vez el proyecto sofware para poder gestionarlo cómodamente y de manera segura ante eventuales contribuyentes.