
Desde hace unos años se viene implantando una cultura de rendir cuentas y de la transparencia. Una de las forma más fáciles para mostrar aquellos resultados o datos que hacen considerarse transparente a una organización, es la creación de una web y publicación de datos en la misma. Pero, ¿una web realmente convierte a una organización en transparente? La respuesta inmediata es no del todo.
Por aquí no pases
En la red existe un protocolo de exclusión de robots para evitar que ciertos bots que analizan los sitios web u otros robots que investigan todo o una parte del acceso de un sitio Web, público o privado, agreguen información innecesaria a los resultados de búsqueda. A tal efecto en la raíz de cualquier sitio web, es posible especificar un archivo "robots.txt" con dichas exclusiones. El fichero robots.txt es un archivo de texto que dicta unas recomendaciones para que todos los crawlers y robots de buscadores cumplan.

Se dice que son recomendaciones, porque un archivo robots.txt en un sitio web, funcionará como una petición que especifica que determinados robots no hagan caso a archivos o directorios específicos en su búsqueda. Este protocolo es consultivo y se confía en la cooperación de los robots del sitio Web, de modo que marca una o más áreas de un sitio fuera de los límites de búsqueda con el uso de un archivo robots.txt, aunque éste no necesariamente garantice aislamiento completo.
Algunos administradores de sitios Web utilizan el archivo robots.txt para hacer algunas secciones privadas, invisibles al resto del mundo, pero dado que los archivos están disponibles de forma pública, su contenido podría ser visto de todas maneras por cualquier persona con un navegador Web y conocimientos medianamente avanzados. En algunos casos el incluir un directorio en este archivo, anuncia de su presencia a posibles hackers.
Esta práctica además puede conllevar la intención de no cachear e indexar ciertos contenidos en la Red a fin de no dejar huella en Internet. A día de hoy Google (con su Googlebot) cachea la información de cualquier web y es posible acceder a la información incluso aunque la web esté caída. Google actualiza y/o elimina la información cacheada de una web según evoluciona el sitio web. Además Google utiliza distintos bots rastreadores para cada tipo de contenido o actividad, los cuales hacen más óptimo la indexación y cacheo de las webs.
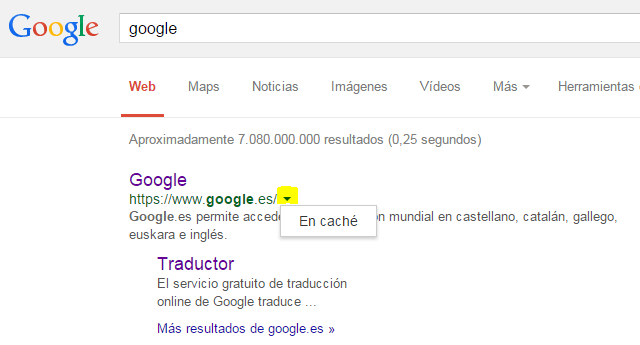
Para cualquier resultado web en Google, existe la posibilidad de entrar a la versión cacheada desde la flecha que apunta hacia abajo al final de la dirección.
Por otro lado existen servicios como Wayback Machine que cachean e indexan webs, de tal forma que es posible acceder al estado de una determinada web para una fecha concreta. Digamos que hace fotografías del estado de los sitios web y los va guardando para su consulta en un futuro, como si de un diario se tratase.
El fichero robots.txt
Estructuralmente el fichero robots.txt tiene esta pinta:
User-agent: * Disallow: /gestion/ Disallow: /imgcache/ Disallow: /demos/ Disallow: /demoweb/ Disallow: /boletines/ Disallow: /grtp/ Disallow: /baliabideak/ Disallow: /dir_phplist/ Disallow: /adjuntos/ Disallow: /partekatzeko/ Disallow: /phplist/ Disallow: /swf/
El campo User-agent especifica los bots que deben respetar el fichero. En nuestro ejemplo, el * quiere decir que todos lo deben cumplir. A continuación se añade un linea con el campo Disallow para cada directorio o recurso que no queramos que sea indexado y cacheado. Del mimos modo existe el campo Allow si se quiere explicitar algún directorio o recurso, pero no se usa ya que por defecto la mayoría de bots rastreará todo el contenido que encuentre, a no ser que encuentre alguna exclusión (disallow). Es fácil encontrar estos archivos en muchas webs, añadiendo /robots.txt a la dirección principal.
Ejemplo: http://www.google.es/robots.txt
Podéis encontrar más información sobre el fichero robots.txt en la siguiente dirección:
http://www.emezeta.com/articulos/robots-txt-todo-lo-que-deberia-saber
Conclusión
Volviendo a la pregunta con la que habríamos el artículo, una web no quiere decir transparencia por sí misma, aunque éste sea su fin último, puesto que el uso de un fichero robots.txt para ocultar recursos y directorios a ojos robots de indexación, propicia no dejar huella y dificultar la trazabilidad de un recurso a lo largo de su existencia en la Red.