
En ocasiones, por cuestiones de diseño es necesario mantener una estructura de carpetas determinada. Si además trabajas con Git te habrás dado cuenta que Git no añade un directorio vacío (ya sea una carpeta o varias anidadas) al proyecto. Siempre tiene que haber un archivo para que Git haga el tracking y añada la estructura de carpetas.
Si además dicho directorio quieres que se excluya del tracking de archivos, la cosa se pone un pelín más complicada, pero nada que no se pueda configurar con un poco de tino 😉 .
Para resolver el problema, en Git es necesario crear un archivo para que la estructura de carpetas se añada al tracking del proyecto. Por ello es necesario generar un fichero "dummy", un fichero vacío en el nivel más bajo del directorio, que sirva de baliza para que Git nos incluya la ruta completa de carpetas que nos permita llegar al archivo. Con esto ya tenemos solucionado el tema del directorio, poniendo ficheros "dummy" en los niveles más bajos del directorio.
Ahora es necesario realizar una acción que nos excluya todos los ficheros del directorio en cuestión, menos los ficheros "dummy" que nos hacen de baliza. Para ello en la raíz del proyecto, definiremos un fichero ".gitignore" que sirve para manejar exclusiones del tracking de ficheros para el proyecto. Lo ficheros o grupos de ficheros definidos en las reglas de ".gitignore" se comportan como ficheros que no existen para Git, y evita proponerlos para incluirlos en un eventual commit.
Creando un caso simple que sirva de ejemplo, excluiremos la carpeta "test" de la ruta "config/test/" de un proyecto.
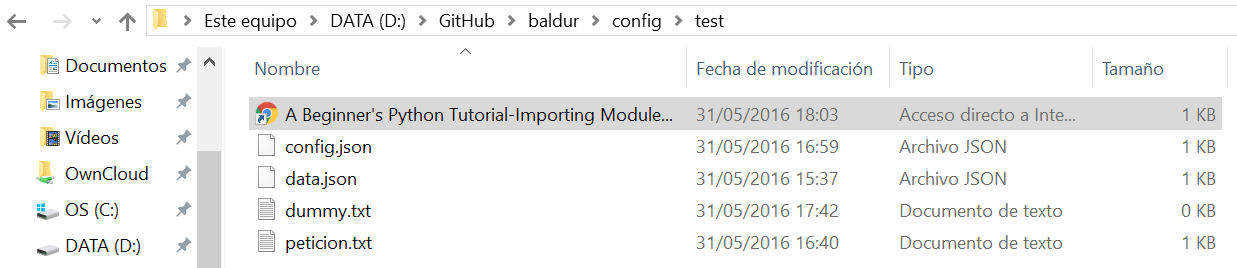
La configuración del fichero ".gitignore" sería la siguiente:
config/test/*
!config/test/dummy.txt
El fichero consta de dos líneas. Una primera línea que excluye todo el directorio del tracking y una segunda línea que excluye el fichero "dummy" de la exclusión de la primera línea. Es importante el orden de las líneas y no son conmutables, ya que el fichero es interpretado de manera secuencial desde la primera línea hasta la última.
Con estas dos sencillas líneas podemos crear estructuras de ficheros, dentro del proyecto, para las cuales no queremos hacer seguimiento de cambios en sus ficheros. Esto es útil para generar estructuras donde alojar ficheros con los que probar el código del proyecto, pero los cuales no queremos añadir al proyecto porque no nos interese (por la razón que sea). También pueden ser útiles estas estructuras estáticas, en los casos en los que el usuario final, introducirá algún tipo de fichero que consuma nuestro proyecto.
Una mejor opción 🧬 [28/02/2021]
Un iteración más elegante es usar varios ficheros ".gitignore". Sobre todo en el caso de que queramos excluir un directorio y todos sus posibles subdirectorios.
⚠️ El uso de ficheros ".gitignore" de manera indiscriminada y descontrolada puede ser constraproducente si no existe una organización o una estrategia previa en su uso en el repositorio del proyecto. Git busca recursivamente y aplica todos los ficheros ".gitignore" que se encuentre dentro del repositorio.
La estrategia sería definir un fichero ".gitignore" dentro de la carpeta (y subcarpetas) que queramos que sean ignoradas, añadiendo como excepción el propio fichero para que Git nos permita añadirlo. El contenido del fichero sería el siguiente:
# Este directorio y subdirectorios son ignorados
*
# Indicamos que .gitignore es la única excepción
!.gitignore
El fichero consta de dós línea, la primera excluye absolutamente todo y la segunda añade como excepción el propio fichero para que pueda ser incluido en el árbol de versionado Git y no sea también excluido. De esta forma tenemos una forma sencilla en la que añadiendo ese fichero ".gitignore" a cualquier directorio, estaremos ignorando el contenido de dicho directo y subdirectorios.