Hay gente que a día de hoy sigue sin entender la diferencia entre Git (herramienta de versionado) y GitHub (plataforma para alojar proyectos Git, ahora propiedad de Microsoft). Y mucho menos entiende el valor que aportan plataformas web como son GitHub, GitLab o Gogs, que añaden todo el valor social y de discusión sobre los cambios propuestos por otros desarrolladores o usuarios, permitiendo así el Desarrollo Colaborativo y auge que hoy en día presenta la filosofía de software Open Source.
Siendo así, vamos a aclarar que Git es una estupenda herramienta de versionado y sincronización de código, o cualquier fichero que no sea binario, permitiendo establecer la sucesión cronológica y relacionar los cambios entre sí para una control y revisión del avance de un proyecto.
Pero por otro lado Git solo, es bastante "cojo" por así decirlo. Las personas no nos relacionamos y trabajamos mediante protocolos o herramientas que llevamos instaladas y que nos permitan trabajar en equipo de manera eficaz 🤣. Es aquí donde entran las plataformas web que dan esa capa social que permiten a los desarrolladores y contribuidores al proyecto comunicarse, establecer criterios, marcar pautas, organizarse, revisar secciones de código... En este artículo nos vamos a centrar en el proceso de revisión de aportes de código Pull Request, abreviados y conocidos como PR.
Esquema básico del proceso de revisión:
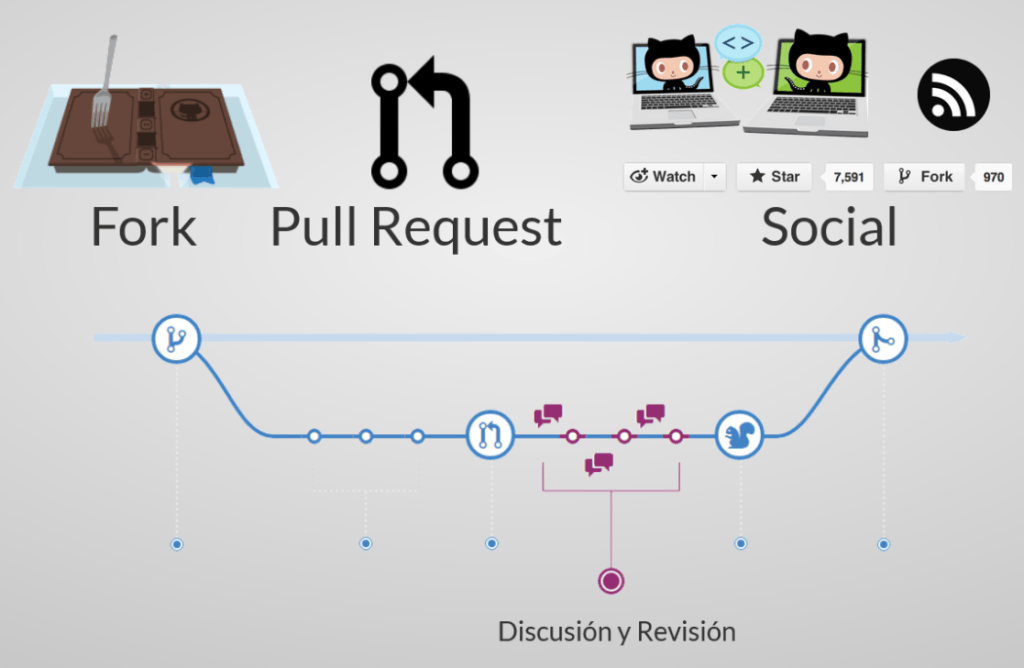
Antes de empezar vamos a aclarar una serie de términos que creo que es conveniente definir. Lo primero explicar lo que es un Fork, que no es más que un clon de un proyecto cuya propiedad (en términos de administración) es de otro usuario u otra organización, pero permanece relacionado con su proyecto originario del que se hizo fork (normalmente se denomina al proyecto origen upstream). Y luego lo que es un Pull Request (de ahora en adelante PR), que es una petición que se hace al proyecto originario (upstream) para que incluya los cambios que tenemos en una de las ramas de nuestro repositorio "forkeado".
Entre el PR y la aceptación del mismo está lo que se conoce como discusión y revisión de los cambios propuestos. Los procesos de revisión son importantes porque permiten afinar los cambios, corregir metodologías de trabajo, realizar pruebas de integración con plataformas como AppVeyor o TravisCI... Podríamos decir que es el punto en el que se comunican las personas involucradas en la propuesta de PR.
Entrando en el terrenos práctico la discusión se genera en la sección de PR y es donde se produce toda la conversación. Aquí podéis ver un ejemplo:
- https://github.com/RDCH106/pycoinmon/pull/5
Creo bastante evidente como se debate, ya que es como un foro en el que dependiendo de la plataforma (GitHub, GitLab o Gogs...) será más completo o menos.
La pregunta del millón es cómo probamos el código que está en el PR. No se encuentra en una rama del repositorio el PR, realmente se encuentra en la rama del que nos hace el PR (a donde podemos ir para probar los cambios). De hecho lo interesante es que el PR puede ir cambiando, si el autor del PR en su fork, en la rama que usó para el PR, realiza cambios. Es decir, un PR no es un elemento estático sujeto a un commit concreto, sino que es la referencia a una rama del proyecto fork que contiene cambios que el upstream no tiene. El truco reside en que comparten la misma base de código y los cambios del PR son la diferencia entre la rama del proyecto upstream al que se le propone el PR y la rama del proyecto fork que contiene los cambios.
Pero esto es una verdad a medias... y digo a medias porque un PR sí es una rama, realmente es una referencia en el repositorio remoto (donde hacemos pull y push). Y eso es bueno 😁. La referencia entre un fork y su upstream nunca se rompe de manera oficial (existen por ejemplo mecanismos en GitHub para solicitar que un fork de un proyecto deje de estar relacionado con su upstream), por lo que asumiremos que un fork es como un padre y un hijo, pueden no llevarse bien pero eso nunca hará que desaparezca la relación parental padre-hijo. Cada vez que la rama del fork desde la que se hace PR se actualiza, la del proyecto upstream también queda actualizada. Por eso resulta conveniente usar ramas para hacer PR de diferentes features (características) que vamos a desarrollar, ya que así podremos mantener de manera independiente ambos paquetes de trabajo sin que haya interferencias entre ellos, y pudiendo dejar la rama el tiempo que haga falta hasta que finalmente se incluyan los cambios al proyecto upstream.
A causa de lo comentado antes podemos revisar desde la consola las referencias remotas con las que cuenta un proyecto git con el comando "git ls-remote". Voy a usar el proyecto pyCOINMON como ejemplo totalmente práctico:
rdch106@RDCH106 MINGW64 /d/GIT/pycoinmon (develop)
$ git ls-remote
From https://github.com/RDCH106/pycoinmon.git
be75cbb0e449383fd42c9033a8b76c844fcfef17 HEAD
d01ecf133c342f490030b56066ed8ff18b36f124 refs/heads/develop
be75cbb0e449383fd42c9033a8b76c844fcfef17 refs/heads/master
ec9c10b6d88274a1a006ae139856de478876572c refs/pull/1/head
c0cb91e1776632494a23cf181584c1903516a758 refs/pull/11/head
46f2e6db3d22a4a48dcf3680157c95641123095d refs/pull/2/head
035e64652c533a569c6b236f54e12aff35ad82b1 refs/pull/3/head
0f08bd644912e7de4a3bc53e3a8d0dbd64d6fc34 refs/pull/4/head
87ef8ca9af3eb5a523d3ef532fccee91aeedcd44 refs/pull/5/head
896d697e846649c7f23b9af3430067451ab5c089 refs/pull/7/head
d57455a8acf719cd3acea623f0759c6e11baada1 refs/pull/7/merge
d6f4c5a4b3e2b0025d74e9feed2609ba50835950 refs/tags/v0.1.0
be413f410cfa23e1f0f2715f2714874a22757b0d refs/tags/v0.1.0^{}
cdc5e356b6d7f829e83a1b0a25e2a7304844223b refs/tags/v0.1.4
4b69c059196f1f41bafc4f5970afb8a34817b509 refs/tags/v0.1.4^{}
b5649af39db2738481751f07b6ad59585144dbd0 refs/tags/v0.2.4
c3506ed1289f3dbcddb2db68201a114a9d1cf8b3 refs/tags/v0.2.4^{}
f0c564d2617d42c0fcb3cb842122a214a6021d37 refs/tags/v0.2.6
a3fe8f8b788311c1d4f5ee906cf2a4c70ffac8db refs/tags/v0.2.6^{}
cea535e4e663531454b437ee8d7976a06e1ae415 refs/tags/v0.2.8
080192d1d7eb33feed6b92df2b389b39592545a6 refs/tags/v0.2.8^{}
9c374d2031a9da655be44e0c79944166cbf99e8a refs/tags/v0.3.2
f76f78252863d372fde5d6ff197ba7519f7da50b refs/tags/v0.3.2^{}
cc248bbd64f177a9b6041cad7c269b880c21b355 refs/tags/v0.3.5
fd50d344575e54def4b841221b2b5c2e8a0a74e3 refs/tags/v0.3.5^{}
7727986a93ce65c2deb905fcd92718c43f3e61ca refs/tags/v0.4.0
aa2df260dc9c1ae9c1aa88ddd7d2498b451bf0fc refs/tags/v0.4.0^{}
a620d5e379d495c69926d97a33803e91b3c07783 refs/tags/v0.4.4
d0b3fa9ae73a15ff17a47804fbbac80245c028c1 refs/tags/v0.4.4^{}
f12102dfacc530f90600082a97a0533ba862bd2c refs/tags/v0.4.7
4329b9f5a9782071fe661376225df6d8d6dfa47e refs/tags/v0.4.7^{}
1d3dbf367ab319f0d9a515c007ff07b90de6ca1c refs/tags/v0.4.8
d01ecf133c342f490030b56066ed8ff18b36f124 refs/tags/v0.4.8^{}
Nos vamos a centrar por ejemplo en el PR #7 que es uno de los que tenemos abiertos y cuyos cambios supongamos que queremos probar:

Lo que vamos a hacer es traernos los cambios del PR basándonos en su ID (en nuestro caso #7), creando una nueva rama (PR_7) para poder probarlo por separado:
rdch106@RDCH106 MINGW64 /d/GIT/pycoinmon (develop)
$ git fetch origin pull/7/head:PR_7
remote: Enumerating objects: 7, done.
remote: Counting objects: 100% (7/7), done.
remote: Total 10 (delta 7), reused 7 (delta 7), pack-reused 3
Unpacking objects: 100% (10/10), done.
From https://github.com/RDCH106/pycoinmon
* [new ref] refs/pull/7/head -> PR_7
Ahora sólo resta hacer un checkout a PR_7:
rdch106@RDCH106 MINGW64 /d/GIT/pycoinmon (develop)
$ git checkout PR_7
Switched to branch 'PR_7'
O hacerlo desde el maravilloso SourceTree el cual os recomiendo como herramienta profesional para la gestión de vuestros repositorios Git locales y remotos (si eres usuario GNU/Linux no me olvido de ti, te recomiendo GitKraken).
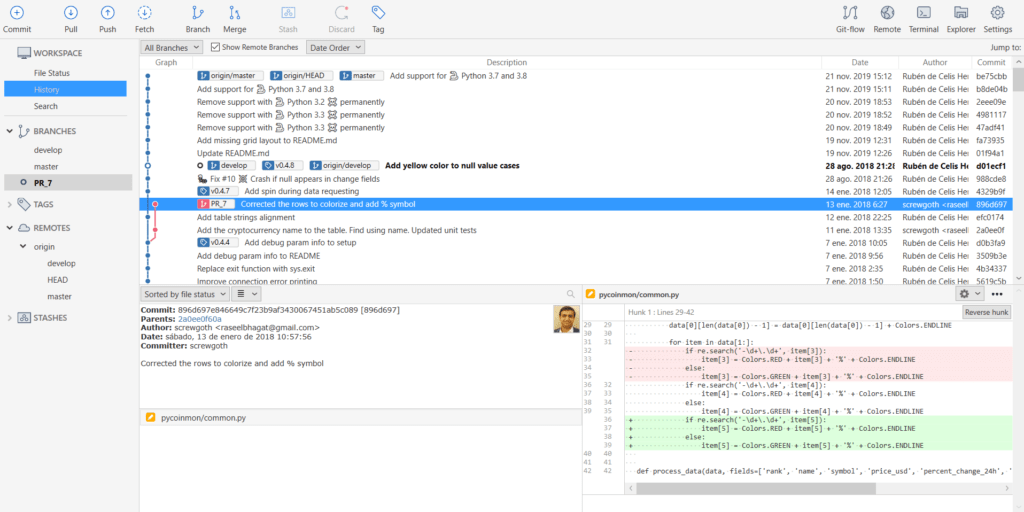
A partir de aquí ya es hacer lo que quieras. Puedes probar los cambios, hacer algunas pruebas, hacer un "merge" para incluir los cambios en otra rama o incluso en la propia rama master.
En lo que a mí respecta, recomiendo simplemente probar los cambios y en la zona de discusión que comentaba antes, realizar todas las apreciaciones necesarias y dejar las cosas lo más claras posible, siendo responsabilidad del desarrollador que hizo el PR realizar los cambios para evitar conflictos. Una vez esté todo correcto, también recomiendo realizar el merge desde GitHub, GitLab o Gogs...
Además todo este proceso forma parte del aprendizaje y democratización de los conocimientos, haciendo de cada PR un sitio al que se puede volver para aprender y revisar lo ocurrido gracias a la trazabilidad en la discusión de los cambios.
Personalmente los procesos de revisión es una base estupenda junto al Planning Poker (prueba https://scrumpoker.online), para igualar las habilidades y competencias que permiten acortar divergencias entre las estimaciones de un grupo de desarrollo ante la planificación de las cargas de trabajo. Yo personalmente soy partidario de que el que lanzó la estimación más alta en la partida de poker realice el paquete de trabajo para que baje su estimación y aumenten sus habilidades, gracias a la supervisión (revisión) de quien dio la cifra más baja, que se asume que dio una estimación más ajustada por unas habilidades mayores.


