Habitualmente una de las cosas que nos interesa medir cuando programamos código, es el tiempo de ejecución. Identificar las secciones de código que más impactan en el tiempo de ejecución total, nos permite optimizar el código y disminuir el tiempo de ejecución general de todo nuestro código.
En C++ hay varias formas de hacerlo, pero dependiendo de cómo lo implementemos y qué cabeceras usemos, podemos encontrarnos que al compilar nuestro código en ciertos sistemas no nos funcione. El siguiente ejemplo muestra cómo medir tiempos en una sección de código utilizando cabeceras estándar de C++:
#include <iostream>
#include <ctime>
unsigned t0, t1;
t0=clock()
// Code to execute
t1 = clock();
double time = (double(t1-t0)/CLOCKS_PER_SEC);
cout << "Execution Time: " << time << endl;
La función "clock" retorna el tiempo consumido por el programa medido en ticks, que junto con la macro "CLOCKS_PER_SEC" nos permite traducir los ticks a segundos.
Desde hace unos años se viene implantando una cultura de rendir cuentas y de la transparencia. Una de las forma más fáciles para mostrar aquellos resultados o datos que hacen considerarse transparente a una organización, es la creación de una web y publicación de datos en la misma. Pero, ¿una web realmente convierte a una organización en transparente? La respuesta inmediata es no del todo.
Por aquí no pases
En la red existe un protocolo de exclusión de robots para evitar que ciertos bots que analizan los sitios web u otros robots que investigan todo o una parte del acceso de un sitio Web, público o privado, agreguen información innecesaria a los resultados de búsqueda. A tal efecto en la raíz de cualquier sitio web, es posible especificar un archivo "robots.txt" con dichas exclusiones. El fichero robots.txt es un archivo de texto que dicta unas recomendaciones para que todos los crawlers y robots de buscadores cumplan.
Se dice que son recomendaciones, porque un archivo robots.txt en un sitio web, funcionará como una petición que especifica que determinados robots no hagan caso a archivos o directorios específicos en su búsqueda. Este protocolo es consultivo y se confía en la cooperación de los robots del sitio Web, de modo que marca una o más áreas de un sitio fuera de los límites de búsqueda con el uso de un archivo robots.txt, aunque éste no necesariamente garantice aislamiento completo.
Algunos administradores de sitios Web utilizan el archivo robots.txt para hacer algunas secciones privadas, invisibles al resto del mundo, pero dado que los archivos están disponibles de forma pública, su contenido podría ser visto de todas maneras por cualquier persona con un navegador Web y conocimientos medianamente avanzados. En algunos casos el incluir un directorio en este archivo, anuncia de su presencia a posibles hackers.
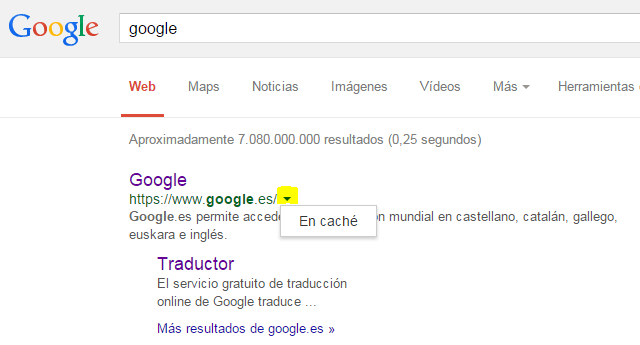
Esta práctica además puede conllevar la intención de no cachear e indexar ciertos contenidos en la Red a fin de no dejar huella en Internet. A día de hoy Google (con su Googlebot) cachea la información de cualquier web y es posible acceder a la información incluso aunque la web esté caída. Google actualiza y/o elimina la información cacheada de una web según evoluciona el sitio web. Además Google utiliza distintos bots rastreadores para cada tipo de contenido o actividad, los cuales hacen más óptimo la indexación y cacheo de las webs.
Para cualquier resultado web en Google, existe la posibilidad de entrar a la versión cacheada desde la flecha que apunta hacia abajo al final de la dirección.
Por otro lado existen servicios como Wayback Machine que cachean e indexan webs, de tal forma que es posible acceder al estado de una determinada web para una fecha concreta. Digamos que hace fotografías del estado de los sitios web y los va guardando para su consulta en un futuro, como si de un diario se tratase.
El fichero robots.txt
Estructuralmente el fichero robots.txt tiene esta pinta:
El campo User-agent especifica los bots que deben respetar el fichero. En nuestro ejemplo, el * quiere decir que todos lo deben cumplir. A continuación se añade un linea con el campo Disallow para cada directorio o recurso que no queramos que sea indexado y cacheado. Del mimos modo existe el campo Allow si se quiere explicitar algún directorio o recurso, pero no se usa ya que por defecto la mayoría de bots rastreará todo el contenido que encuentre, a no ser que encuentre alguna exclusión (disallow). Es fácil encontrar estos archivos en muchas webs, añadiendo /robots.txt a la dirección principal.
Volviendo a la pregunta con la que habríamos el artículo, una web no quiere decir transparencia por sí misma, aunque éste sea su fin último, puesto que el uso de un fichero robots.txt para ocultar recursos y directorios a ojos robots de indexación, propicia no dejar huella y dificultar la trazabilidad de un recurso a lo largo de su existencia en la Red.
En mi día a día trabajo con información tridimensional y hago tratamiento de la misma mediante una herramienta que se ha convertido para mí en un imprescindible. Se trata de Meshlab.
Meshlab es una herramienta Open Source muy potente que permite el manejo y procesamiento de información 3D. Lo que hace realmente potente a Meshlab, son la cantidad de filtros para procesar esa información, y que más de uno ha pensado en usar como herramienta para hacer cierto procesamiento de un Dataset de información.
Cuando se descargan los binarios de Meshlab, se incluyen dos ejecutables: meshlab y meshlabserver. El primero es obvio para qué sirve, porque se trata del ejecutable que lanza Meshlab para ser utilizado por medio de la interfaz gráfica. El segundo es una ejecutable que nos permite procesar un Dataset completo, usando los filtros de Meshlab, mediante la configuración de un script MLX y prescindiendo de la interfaz gráfica.
Generar el script es tan sencillo como abrir Meshlab y aplicar todos los filtros que deseemos en el Dataset. Veamos un ejemplo.
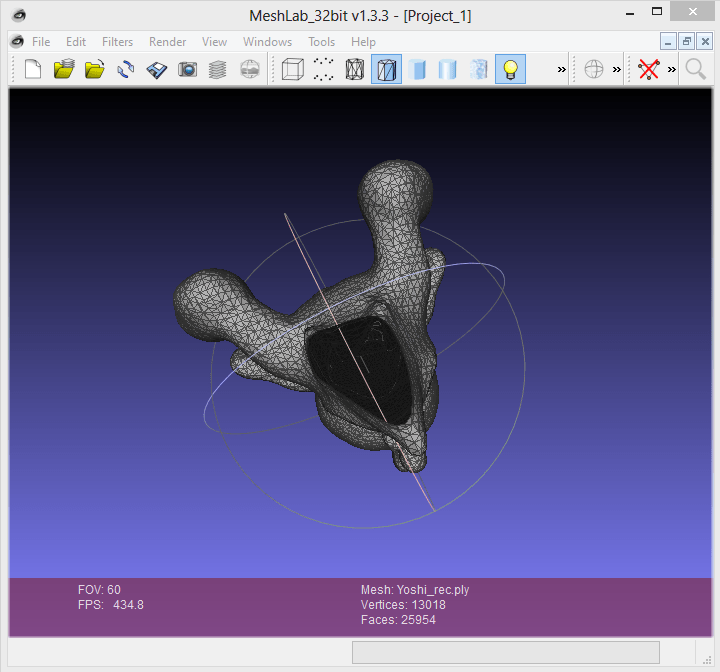
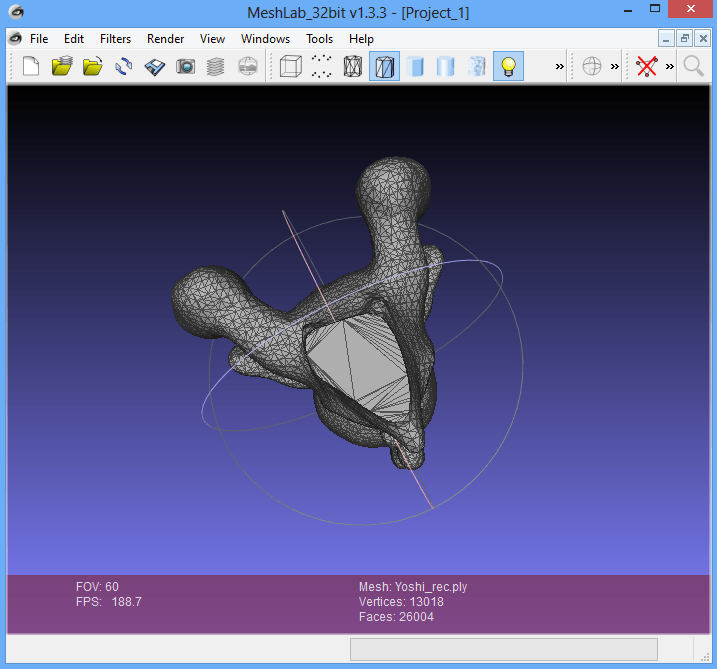
Tenemos la malla de un modelo 3D de Yoshi como Dataset, pero dicho modelo tiene un agujero en la parte inferior.
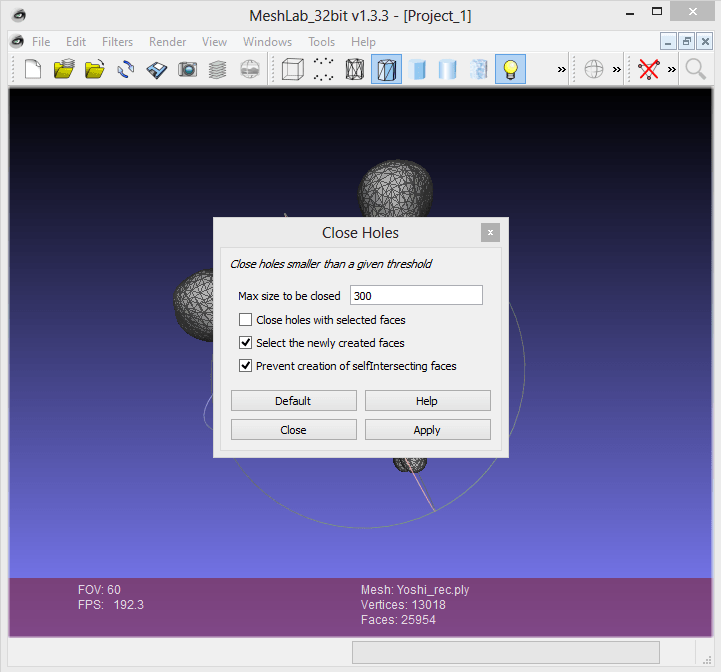
Meshlab dispone entre sus filtros de uno que se llama "Close Holes", que nos vendrá de perlas para este caso. Vamos a la sección "Filters" y los buscamos.
Parametrizamos el filtro como mejor consideremos y le damos a aplicar. Como podemos ver el agujero de la parte inferior queda cerrado.
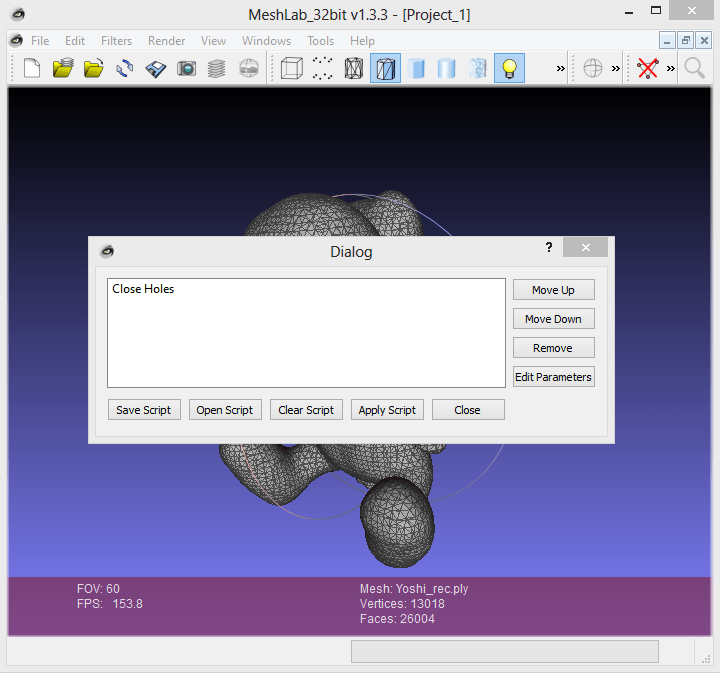
Para generar el script del filtro que acabamos de aplicar y que vemos que da buenos resultados, volvemos a ir a "Filters", y seleccionamos "Show current filter script". Se nos abrirá una ventana como la siguiente:
Aquí están todas las acciones que van a constituir nuestro script, en nuestro caso sólo vamos a usar "Close Holes". En esta ventana podemos editar el orden de los filtros que vamos a aplicar, los parámetros de cada script, borrar un filtro del script... Cuando todo está en orden guardamos el script, el cual será guardado en formato MLX.
Para aplicar las acciones en lote sólo tenemos que usar el ejecutable meshlabserver indicándole los parámetros necesarios para su funcionamiento (input, output y script de filtros XML). Para ver la parametrización de meshlabserver podemos acudir a su comando de ayuda de la siguiente forma:
meshlabserver -help
Usage:
meshlabserver arg1 arg2 ...
where args can be:
-i [filename...] mesh(s) that has to be loaded
-o [filename...] mesh(s) where to write the result(s)
-s filename script to be applied
-d filename dump on a text file a list of all the filtering fucntion
-l filename the log of the filters is ouput on a file
-om options data to save in the output files: vc -> vertex colors, vf -> vertex flags, vq -> vertex quality, vn-> vertex normals, vt -> vertex texture coords, fc -> face colors, ff -> face flags, fq -> face quality, fn-> face normals, wc -> wedge colors, wn-> wedge normals, wt -> wedge texture coords
Example:
'meshlabserver -i input.obj -o output.ply -s meshclean.mlx -om vc fq wn'
Notes:
There can be multiple meshes loaded and the order they are listed matters because
filters that use meshes as parameters choose the mesh based on the order.
The number of output meshes must be either one or equal to the number of input meshes.
If the number of output meshes is one then only the first mesh in the input list is saved.
The format of the output mesh is guessed by the used extension.
Script is optional and must be in the format saved by MeshLab.
De esta forma podemos aplicar una sucesión de operaciones de Meshlab en el Dataset que queramos con muy poco esfuerzo.
SyntaxHighlighter es un completo coloreador de sintaxis desarrollado en JavaScript. Al ser un desarrollo de JavaScript la ejecución se realiza en el lado del cliente, en el navegador, lo que no añade carga extra al servidor.
Oficialmente soporta la detección de sintaxis para los siguientes lenguajes: